V2EX 热门帖子
1. 你真的敢让 AI 自主编写代码吗?
作为一个程序员,如果你的 AI 助手突然提交了一个它自己重构过的、性能提升 10 倍但你完全看不懂的底层内核 PR ,你会选择点击“Merge”吗?
作者: elishuhu | 发布时间: 2026-03-20 14:08
2. Android 是真 TM 难用
之前一直用的是 iPhone ,当主力机用了两三年,最近心血来潮换了安卓 (某旗舰),想着“自由度高、可玩性强”,结果用了一个多月,结论就一句话:Android 真 TM 难用。
说几个最离谱的点:
1.通知系统看起来很强,实际一团乱麻
表面上说什么“通知通道精细管理”,结果实际体验就是——大部分 App 根本不按规范来。
有的全塞一个通道,有的命名乱七八糟,有的干脆不给你细分。你想只关营销推送?不好意思,要么全关,要么继续被轰炸。
尤其是国内这些 App ,和你想象的“可控”完全不是一回事。
2.系统割裂严重,每家都在自创标准
用过几个品牌:小米、OPPO 、vivo ,甚至 三星。
每家一套逻辑:权限管理不一样、后台机制不一样、设置入口也不一样。
你换个手机,相当于重新学习一遍系统,这在 iOS 上基本不存在。
3.后台机制玄学,完全不可预测
官方说“不卡后台”“大内存”,结果现实是:
你以为它在?其实没了。
你以为它没了?它又突然活了。
像 Clash 这种需要常驻的工具,经常莫名其妙断掉。
各种“电池优化白名单”“锁后台”“自启动”,全开了也不一定有用,纯玄学。
4.应用质量参差不齐,体验极不稳定
同一个 App ,在不同安卓机上表现都不一样:
卡顿、掉帧、适配问题、闪退,时不时就来一下。
很多开发者明显是“先适配 iOS ,再糊一个安卓版本”,用起来就是明显粗糙一档。
5.权限系统看似自由,其实非常烦
动不动就弹权限:位置、后台、通知、悬浮窗、自启动……
而且很多功能不给权限就直接不给用。
你要么妥协全开,要么体验残废,所谓“自由”其实是把复杂性转嫁给用户。
6.系统广告和骚操作太多
有些系统级 App 都能给你推广告,文件管理、天气、浏览器,全都有。
你要一个个关,还藏得特别深。
买个几千块的手机,还得自己“去广告”,这事本身就挺离谱。
7.更新策略混乱,版本碎片化严重
安卓版本一堆( 12 、13 、14…),厂商还要再套一层 UI 。
结果就是:
同一个功能,不同机型有没有都不一定。
系统更新?有的快,有的等一年,有的直接没了。
8.生态不统一,小功能全靠拼凑
像剪贴板同步、设备联动这种东西,得看品牌生态。
你用 小米 就配小米全家桶,用 三星 又是另一套。
跨品牌基本等于没有,完全不像 iOS 那种统一体验。——
当然,安卓也不是一无是处:
1.确实自由,能折腾(前提是你愿意花时间)
2.硬件选择多,性价比高
3.有些功能确实比 iOS 激进,比如分屏、窗口化但说实话,这些都是“加分项”。
而基础体验——稳定、统一、可预期——反而做不好。最离谱的是,你去网上搜这些问题:
有人问“能不能更简单点”,下面一堆回复不是说怎么解决,而是——
“你为什么需要这个功能?”我就有点看不懂了,安卓用户的忍耐力是不是也太强了?
目前的结论就是:
安卓适合折腾,当玩具可以;
但要当主力机长期用,真的挺折磨人的。*以上内容通过 AI 生成。
作者: Lutto | 发布时间: 2026-03-21 11:53
3. 你不知道的 Claude Code:架构、治理与工程实践
0. 太长不读
今天这篇文章源于最近半年深度使用 Claude Code 、两个账号每月 40 刀氪金换来的一些踩坑经验,希望能给大伙一些输入。
刚开始我也把它当 ChatBot 用,后来很快发现不对劲:上下文越来越乱、工具越来越多但效果越来越差、规则越写越长却越不遵守,折腾了一段时间,研究了 Claude Code 本身之后才意识到,这不是 Prompt 问题,而是这套系统的设计就是这样的。
这篇文章想和大伙聊聊这几个事:Claude Code 底层怎么运作、上下文为什么会乱以及怎么治理、Skills 和 Hooks 应该怎么设计、Subagents 的正确用法、Prompt Caching 的架构影响,以及怎么写一个真正有用的 CLAUDE.md 。
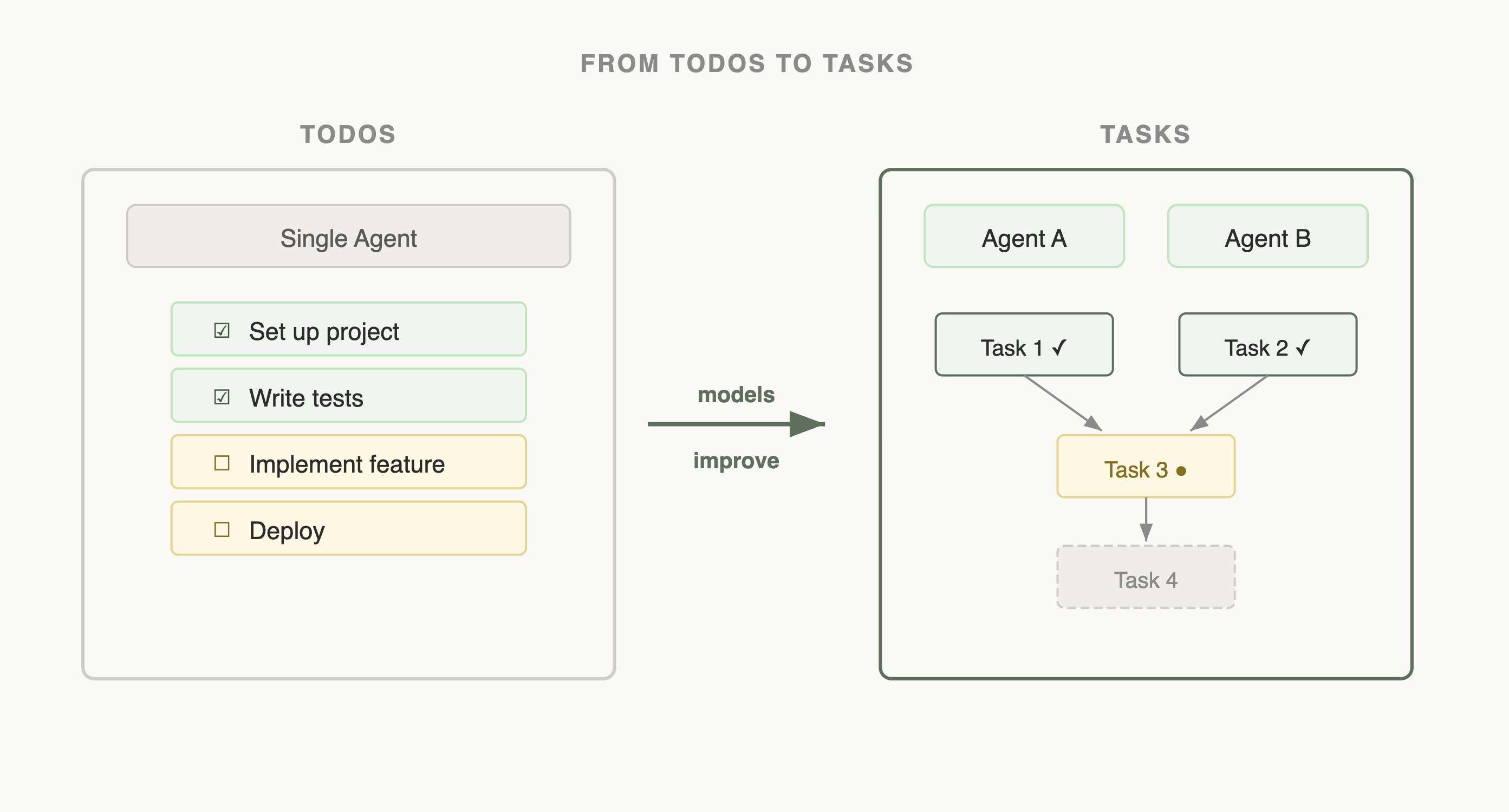
我觉得最直接的理解方式,是把 Claude Code 拆成六层来看:
层 职责 [CLAUDE.md](http://CLAUDE)/ rules / memory长期上下文,告诉 Claude “是什么” Tools/MCP动作能力,告诉 Claude “能做什么” Skills按需加载的方法论,告诉 Claude “怎么做” Hooks强制执行某些行为,不依赖 Claude 自己判断 Subagents隔离上下文的工作者,负责受控自治 Verifiers验证闭环,让输出可验、可回滚、可审计 只强化其中一层,系统就会失衡,CLAUDE.md 写太长,上下文先污染自己了;工具堆太多了,选择就搞不清楚了; subagents 开得到处都是,状态就漂移了;验证这步跳过了,出了问题根本不知道是哪里挂的。
1. 它底层是怎么运行的
Claude Code 的核心不是”回答”,而是一个反复循环的代理过程:
收集上下文 → 采取行动 → 验证结果 → [完成 or 回到收集] ↑ ↓ CLAUDE.md Hooks / 权限 / 沙箱 Skills Tools / MCP Memory用了一段时间才意识到,卡住的地方几乎从来不是模型不够聪明,更多时候是给了它错误的上下文,或者写出来了但根本没法判断对不对,也没法撤回。
真正要关注的五个层面
层面 核心问题 主要载体 Context surface哪些信息常驻,哪些按需加载 [CLAUDE.md](http://CLAUDE)、rules 、memory 、skillsAction surfaceClaude 当前具备哪些动作能力 built-in tools 、MCP 、plugins Control surface哪些动作必须被约束、阻断或审计 permissions 、sandbox 、hooks Isolation surface哪些任务需要隔离上下文和权限 subagents 、worktrees 、forked sessions Verification surface如何判断任务完成且结果可信 tests 、lint 、screenshots 、logs 、CI 对着这几个面看,很多问题就好排查了。结果不稳定,查上下文加载顺序,不是模型的事;自动化失控,看控制层有没有设计,不是 agent 太主动;长会话质量下降,中间产物把上下文污染了,换个新会话比反复调 prompt 有用得多。
2. 概念边界:MCP / Plugin / Tools / Skills / Hooks / Subagents
概念 运行时角色 解决什么 典型误用 [CLAUDE.md](http://CLAUDE)项目级持久契约 每次会话都必须成立的命令、边界、禁止项 写成团队知识库 .claude/rules/*路径或语言相关规则 目录、文件类型或语言级局部规范 所有规则都堆到根 [CLAUDE.md](http://CLAUDE)Built-in Tools内置能力 读文件、改文件、跑命令、搜索 把所有集成都塞进 shell MCP外部能力接入协议 让 Claude 访问 GitHub 、Sentry 、数据库 接太多 server ,工具定义挤爆上下文 Plugin打包分发层 把 Skills/Hooks/MCP 一起分发 把 plugin 当成运行时 primitive Skill按需加载的知识/工作流 给 Claude 一个”方法包” skill 既像百科全书又像部署脚本 Hook强制执行规则的拦截层 在生命周期事件前后执行规则 用 hook 替代所有模型判断 Subagent隔离上下文的工作单元 并行研究、限制工具与权限 无边界 fan-out ,治理失控 简单记:给 Claude 新动作能力用 Tool/MCP ,给它一套工作方法用 Skill ,需要隔离执行环境用 Subagent ,要强制约束和审计用 Hook ,跨项目分发用 Plugin 。
3. 上下文工程:最重要的系统约束
很多人把上下文当”容量问题”,但卡住的地方通常不是不够长,而是太吵了,有用的信息被大量无关内容淹没了。
真实的上下文成本构成
Claude Code 的 200K 上下文并非全部可用:
200K 总上下文 ├── 固定开销 (~15-20K) │ ├── 系统指令: ~2K │ ├── 所有启用的 Skill 描述符: ~1-5K │ ├── MCP Server 工具定义: ~10-20K ← 最大隐形杀手 │ └── LSP 状态: ~2-5K │ ├── 半固定 (~5-10K) │ ├── CLAUDE.md: ~2-5K │ └── Memory: ~1-2K │ └── 动态可用 (~160-180K) ├── 对话历史 ├── 文件内容 └── 工具调用结果
一个典型 MCP Server (如 GitHub )包含 20-30 个工具定义,每个约 200 tokens ,合计 4,000-6,000 tokens 。接 5 个 Server ,光这部分固定开销就到了 25,000 tokens ( 12.5%) 。我第一次算出这个数字的时候,真没想到有这么多,在要读大量代码的场景,这 12.5% 真的很关键。
推荐的上下文分层
始终常驻 → CLAUDE.md:项目契约 / 构建命令 / 禁止事项 按路径加载 → rules:语言 / 目录 / 文件类型特定规则 按需加载 → Skills:工作流 / 领域知识 隔离加载 → Subagents:大量探索 / 并行研究 不进上下文 → Hooks:确定性脚本 / 审计 / 阻断说白了,偶尔用的东西就不要每次都加载进来。
上下文最佳实践
- 保持
[CLAUDE.md](http://CLAUDE)短、硬、可执行,优先写命令、约束、架构边界。Anthropic 官方自己的 CLAUDE.md 大约只有 2.5K tokens ,可以参考- 把大型参考文档拆到 Skills 的 supporting files ,不要塞进 SKILL.md 正文
- 使用
.claude/rules/做路径/语言规则,不让根[CLAUDE.md](http://CLAUDE)承担所有差异- 长会话主动用
/context观察消耗,不要等系统自动压缩后再补救
- 任务切换优先
/clear,同一任务进入新阶段用/compact- **把 Compact Instructions 写进CLAUDE.md**,压缩后必须保留什么由你控制,不由算法猜
Tool Output 噪声:另一个隐形上下文杀手
前面算的是 MCP 工具定义的固定开销,但动态部分同样有个坑容易被忽视:Tool Output 。
cargo test一次完整输出动辄几千行,git log、find、grep在稍大的仓库里也能轻松塞满屏幕。这些输出 Claude 并不需要全看,但只要它出现在上下文里,就是实实在在的 token 消耗,同样会挤掉对话历史和文件内容的空间。后来看到 RTK ( Rust Token Killer ) 这个思路觉得挺对的,它做的事很简单:在命令输出到 Claude 之前自动过滤,只留决策需要的核心信息。比如
cargo test:# Claude 看到的原始输出 running 262 tests test auth::test_login ... ok ...(几千行) # 走 RTK 之后 ✓ cargo test: 262 passed (1 suite, 0.08s)Claude 真正需要知道的就是「过了还是挂了,挂在哪里」,其他都是噪声。它通过 Hook 透明重写命令,对 Claude Code 来说完全无感。
后面第 6 节会提到
| head -30这种手动截断,RTK 干的就是这件事,只是覆盖面更广,不用每条命令自己加。项目 开源在 GitHub。压缩机制的陷阱
默认压缩算法按”可重新读取”判断,早期的 Tool Output 和文件内容会被优先删掉,顺带把架构决策和约束理由 也一起扔了。两小时后再改,可能根本不记得两小时前定了什么,莫名其妙的 Bug 就是这么来的。
解决方案就是在 CLAUDE.md 里写明:
## Compact Instructions When compressing, preserve in priority order: 1. Architecture decisions (NEVER summarize) 2. Modified files and their key changes 3. Current verification status (pass/fail) 4. Open TODOs and rollback notes 5. Tool outputs (can delete, keep pass/fail only)除了写 Compact Instructions ,还有一种更主动的方案:在开新会话前,先让 Claude 写一份 HANDOFF.md ,把当前进度、尝试过什么、哪些走通了、哪些是死路、下一步该做什么写清楚。下一个 Claude 实例只读这个文件就能接着做,不依赖压缩算法的摘要质量:
在 HANDOFF.md 里写清楚现在的进展。解释你试了什么、什么有效、什么没用,让下一个拿到新鲜上下文的 agent 只看这个文件就能继续完成任务。
写完后快速扫一眼,有缺漏直接让它补,然后开新会话,把 HANDOFF.md 的路径发过去就行。
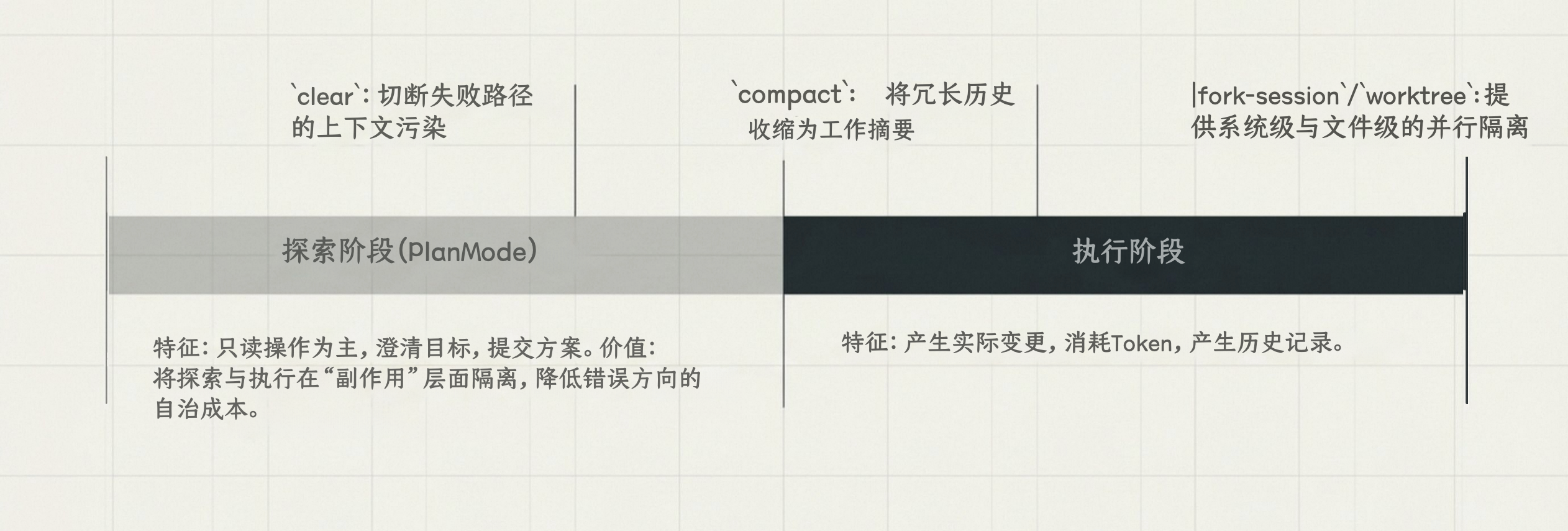
Plan Mode 的工程价值
Plan Mode 的核心是把探索和执行拆开,探索阶段不动文件,确认方案后再执行:
- 探索阶段以只读操作为主
- Claude 可以先澄清目标和边界,再提交具体方案
- 执行成本在计划确认之后才发生
对于复杂重构、迁移、跨模块改动,这样做比”急着出代码”有用多了,在错误假设上越跑越偏的情况会少很多。按两下
Shift+Tab进入 Plan Mode ,进阶玩法是开一个 Claude 写计划,再开一个 Codex 以”高级工程师”身份审这个计划,让 AI 审 AI ,效果很好 。
4. Skills 设计:不是模板库,是用的时候才加载的工作流
Skill 官方描述是”按需加载的知识与工作流”,描述符常驻上下文,完整内容按需加载,用起来和”保存的 Prompt”差别挺大的。
一个好 Skill 应该满足什么
- 描述要让模型知道”何时该用我”,而不是”我是干什么的”,这两个差很多
- 有完整步骤、输入、输出和停止条件,别写了个开头没有结尾
- 正文只放导航和核心约束,大资料拆到 supporting files 里
- 有副作用的 Skill 要显式设置
disable-model-invocation: true,不然 Claude 会自己决定要不要跑Skill 怎么做到”按需加载”
Claude Code 团队在内部设计中反复强调 “progressive disclosure”,意思不是让模型一次性看到所有信息,而是先获得索引和导航,再按需拉取细节:
[SKILL.md](http://SKILL)负责定义任务语义、边界和执行骨架- supporting files 负责提供领域细节
- 脚本负责确定性收集上下文或证据
一个比较稳定的结构长这样:
.claude/skills/ └── incident-triage/ ├── SKILL.md ├── runbook.md ├── examples.md └── scripts/ └── collect-context.shSkill 的三种典型类型
下面几个例子都来自我在开源 terminal 项目 Kaku 里的实际 Skill ,比较直观。
类型一:检查清单型(质量门禁)
发布前跑一遍,确保不漏项:
--- name: release-check description: Use before cutting a release to verify build, version, and smoke test. --- ## Pre-flight (All must pass) - [ ] `cargo build --release` passes - [ ] `cargo clippy -- -D warnings` clean - [ ] Version bumped in Cargo.toml - [ ] CHANGELOG updated - [ ] `kaku doctor` passes on clean env ## Output Pass / Fail per item. Any Fail must be fixed before release.类型二:工作流型(标准化操作)
配置迁移高风险,显式调用 + 内置回滚步骤:
--- name: config-migration description: Migrate config schema. Run only when explicitly requested. disable-model-invocation: true --- ## Steps 1. Backup: `cp ~/.config/kaku/config.toml ~/.config/kaku/config.toml.bak` 2. Dry run: `kaku config migrate --dry-run` 3. Apply: remove `--dry-run` after confirming output 4. Verify: `kaku doctor` all pass ## Rollback `cp ~/.config/kaku/config.toml.bak ~/.config/kaku/config.toml`类型三:领域专家型(封装决策框架)
运行时出问题时让 Claude 按固定路径收集证据,不要瞎猜:
--- name: runtime-diagnosis description: Use when kaku crashes, hangs, or behaves unexpectedly at runtime. --- ## Evidence Collection 1. Run `kaku doctor` and capture full output 2. Last 50 lines of `~/.local/share/kaku/logs/` 3. Plugin state: `kaku --list-plugins` ## Decision Matrix | Symptom | First Check | |---|---| | Crash on startup | doctor output → Lua syntax error | | Rendering glitch | GPU backend / terminal capability | | Config not applied | Config path + schema version | ## Output Format Root cause / Blast radius / Fix steps / Verification command描述符写短点,每个 Skill 都在偷你的上下文空间
每个启用的 Skill ,描述符常驻上下文。优化前后差距很大:
# 低效(~45 tokens ) description: | This skill helps you review code changes in Rust projects. It checks for common issues like unsafe code, error handling... Use this when you want to ensure code quality before merging. # 高效(~9 tokens ) description: Use for PR reviews with focus on correctness.还有一个很重要的
disable-auto-invoke使用策略:
- 高频(>1 次/会话)→ 保持 auto-invoke ,优化描述符
- 低频(<1 次/会话)→ disable-auto-invoke ,手动触发,描述符完全脱离上下文
- 极低频(<1 次/月)→ 移除 Skill ,改为 AGENTS.md 中的文档
Skills 反模式
- 描述过短:
description: help with backend(任何后端工作都能触发,哈哈)- 正文过长:几百行工作手册全塞进 SKILL.md 正文
- 一个 Skill 覆盖 review 、deploy 、debug 、docs 、incident 五件事
- 有副作用的 Skill 允许模型自动调用
5. 工具设计:怎么让 Claude 少选错
我后面越用越觉得,给 Claude 的工具和给人写的 API 不是一回事。给人用的 API 往往会追求功能齐全,但给 agent 用,重点不是功能堆得多完整,而是让它更容易用对。
好工具 vs 坏工具
维度 好工具 坏工具 名称 jira_issue_get,sentry_errors_searchquery,fetch,do_action参数 issue_key,project_id,response_formatid,name,target返回 与下一步决策直接相关的信息 一堆 UUID 、内部字段、原始噪声 规模 单一目标,边界清楚 多个动作混杂,副作用不透明 成本 默认输出受控、可截断 默认返回过大上下文 错误信息 包含修正建议 仅返回 opaque error code 几个实用设计原则:
- 名称前缀按系统或资源分层:
github_pr_*、jira_issue_*- 对大响应支持
response_format: concise / detailed- 错误响应要教模型如何修正,不要只抛 opaque error code
- 能合并成高层任务工具时,不要暴露过多底层碎片工具,避免
list_all_*让模型自行筛选从 Claude Code 内部工具演进学到的
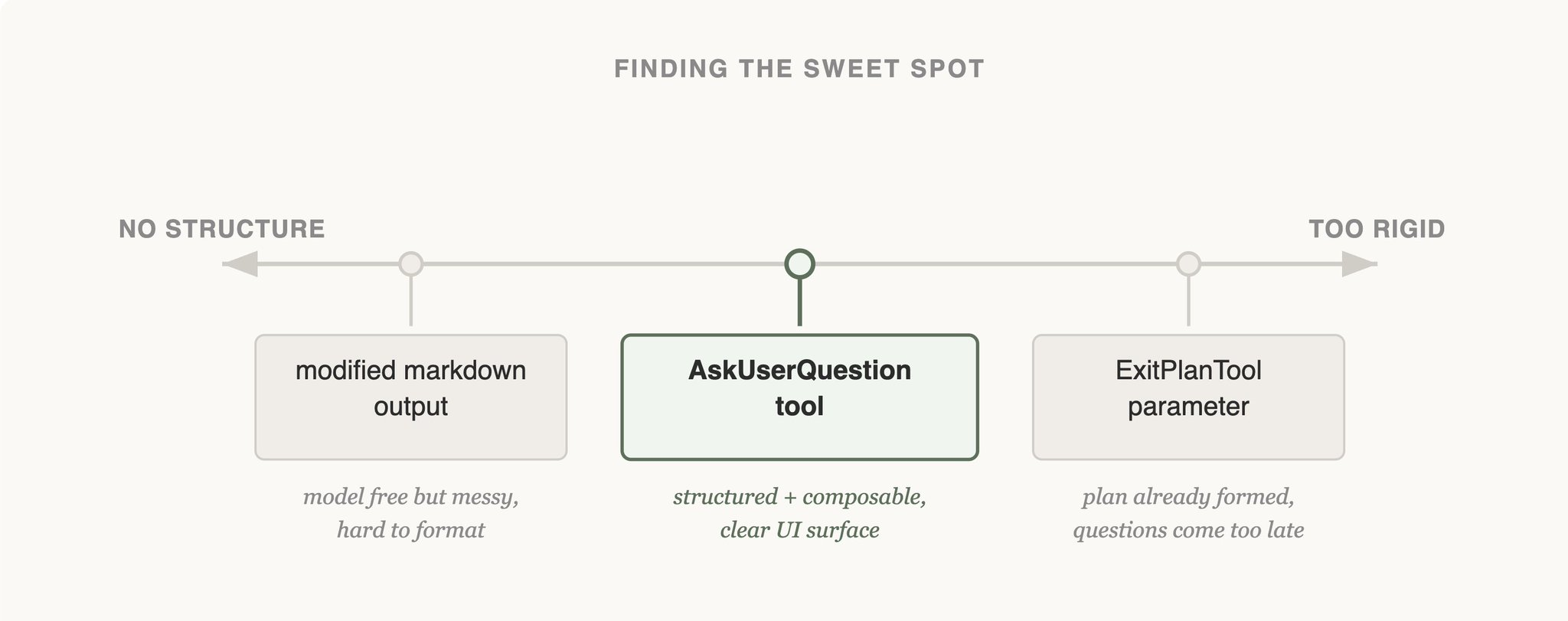
我看到 Claude Code 团队内部工具的这段演进时,感觉还挺有意思。像这种需要在任务中途停下来问用户的场景,他们前后试了三种做法:
- 第一版 :给已有工具(如 Bash )加一个
question参数,让 Claude 在调用工具时顺带提问。结果 Claude 大多数时候直接忽略这个参数,继续往下跑,根本不停下来问。- 第二版 :要求 Claude 在输出里写特定 markdown 格式,外层解析到这个格式就暂停。问题是没有强制约束,Claude 经常”忘了”按格式写,提问逻辑非常脆弱。
- 第三版 :做成独立的
AskUserQuestion工具。Claude 想提问就必须显式调用它,调用即暂停,没有歧义。比前两版靠谱多了。下面这张图刚好能解释,为什么第三版明显更稳:
左边( markdown 自由输出)太松,模型格式随意、外层解析脆弱;右边( ExitPlanTool 参数)太死,等到退出计划阶段提问已经太晚;
AskUserQuestion独立工具落在中间,结构化且随时可调用,是这三者里最稳定的设计。说白了,既然你就是要 Claude 停下来问一句,那就直接给它一个专门的工具。加个 flag 或者约定一段输出格式,很多时候它一顺手就略过去了。
Todo 工具的演进 :
早期用 TodoWrite 工具 + 每 5 轮插入提醒让 Claude 记住任务。随着模型变强,这个工具反而成了限制,Todo 提醒让 Claude 认为必须严格遵循,无法灵活修改计划。挺有意思的教训:当初加这个工具是因为模型不够强,模型变强之后它反而变成了枷锁。值得过段时间回来检查一下,当初加的限制还成不成立。
搜索工具的演进 :最初用 RAG 向量数据库,虽然快但需要索引、不同环境脆弱,最重要的是 Claude 不喜欢用 。改成 Grep 工具让 Claude 自己搜索后,好用很多。后来又发现一个顺带的好处:Claude 读 Skill 文件,Skill 文件又引用其他文件,模型会递归读取,按需发现信息,不需要提前塞进去,这个模式后来被叫做”渐进式披露”。
什么时候不该再加 Tool
- 本地 shell 可以可靠完成的事情
- 模型只需要静态知识,不需要真正与外部交互
- 需求更适合 Skill 的工作流约束,而不是 Tool 的动作能力
- 还没验证过工具描述、schema 和返回格式能被模型稳定使用
6. Hooks:在 Claude 执行操作前后,强制插入你自己的逻辑
Hooks 很容易被当成”自动运行的脚本”,但我自己用下来,觉得它更像是把一些不能交给 Claude 临场发挥的事情,重新收回到确定性的流程里。
比如格式化要不要跑、保护文件能不能改、任务完成后要不要通知,这些事真不要指望 Claude 每次都自己记得。
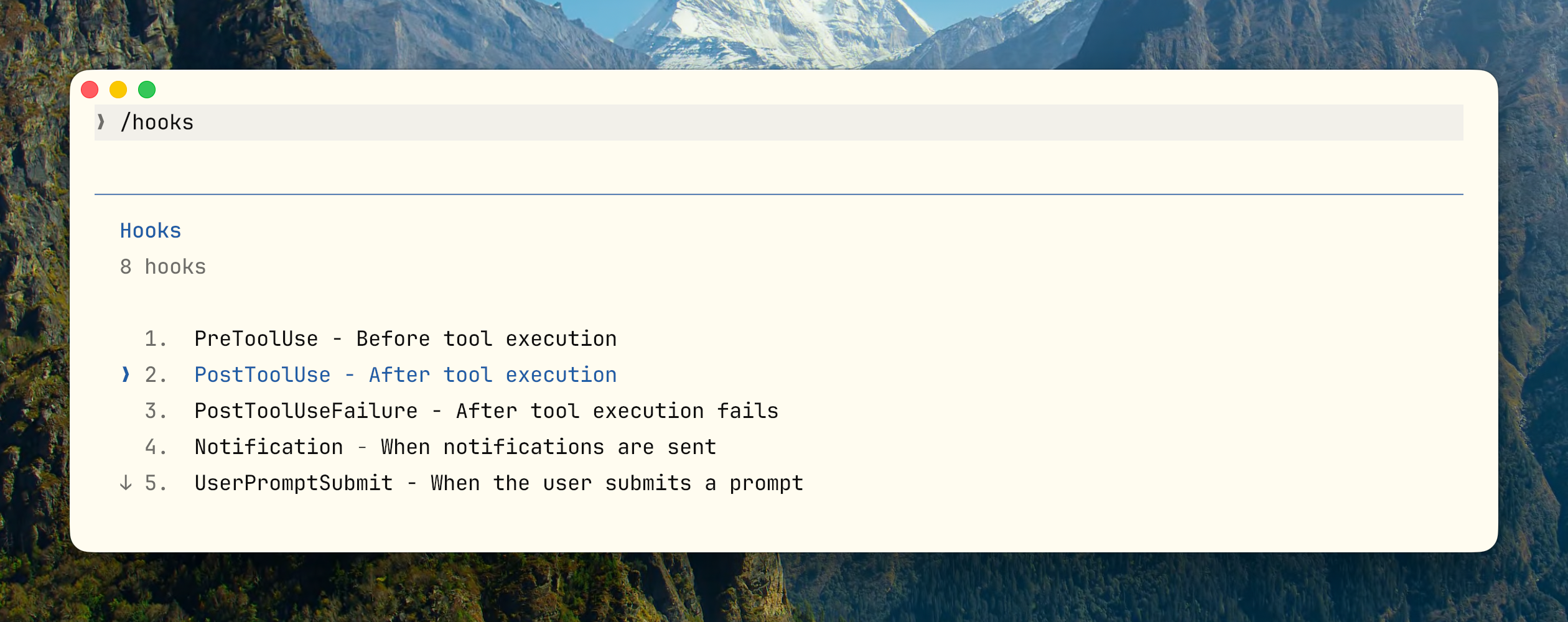
当前支持的 Hook 点
适合 vs 不适合放到 Hooks 的
适合 :阻断修改受保护文件、Edit 后自动格式化/lint/轻量校验、SessionStart 后注入动态上下文( Git 分支、环境变量)、任务完成后推送通知。
不适合 :需要读大量上下文的复杂语义判断、长时间运行的业务流程、需要多步推理和权衡的决策,这些该在 Skill 或 Subagent 里。
{ "hooks": { "PostToolUse": [ { "matcher": "Edit", "pattern": "*.rs", "hooks": [ { "type": "command", "command": "cargo check 2>&1 | head -30", "statusMessage": "Running cargo check..." } ] } ], "Notification": [ { "type": "command", "command": "osascript -e 'display notification \"Task completed\" with title \"Claude Code\"'" } ] } }Hooks:越早发现错误,越省时间
在 100 次编辑的会话中,每次节省 30-60 秒,累积节省 1-2 小时,还挺可观的。注意限制输出长度 (
| head -30),避免 Hook 输出反而污染上下文。如果不想在每条命令后面手动加截断,可以看看第 3 节提到的 RTK ,它把这件事系统化了。Hooks + Skills + CLAUDE.md 三层叠加
[CLAUDE.md](http://CLAUDE):声明”提交前必须通过测试和 lint”Skill:告诉 Claude 在什么顺序下运行测试、如何看失败、如何修复Hook:对关键路径执行硬性校验,必要时阻断用下来感觉,三样少任何一层都会有漏洞。只写 CLAUDE.md 规则,Claude 经常当没看见;只靠 Hooks ,细节判断又做不了,放在一起才比较稳。
7. Subagents:派一个独立的 Claude 去干一件具体的事
Subagent 就是从主对话派出去的一个独立 Claude 实例,有自己的上下文窗口,只用你指定的工具,干完汇报结果。我用下来觉得它最大的价值不是”并行”,而是隔离——扫代码库、跑测试、做审查这类会产生大量输出的事,塞进主线程很快就把有效上下文挤没了,交给 Subagent 做,主线程只拿一个摘要,干净很多。
Claude Code 内置了三个:Explore (只读扫库,默认跑 Haiku 省成本)、Plan (规划调研)、General-purpose (通用),也可以自定义。
配置时要显式约束
tools/disallowedTools:限定能用什么工具,别给和主线程一样宽的权限model:探索任务用 Haiku/Sonnet ,重要审查用 OpusmaxTurns:防止跑飞isolation: worktree:需要动文件时隔离文件系统另一个实用细节:长时间运行的 bash 命令可以按
Ctrl+B移到后台,Claude 之后会用 BashOutput 工具查看结果,不会阻塞主线程继续工作。subagent 同理,直接告诉它「在后台跑」就行。几个常见反模式
- 子代理权限和主线程一样宽,隔离没有意义
- 输出格式不固定,主线程拿到没法用
- 子任务之间强依赖,频繁要共享中间状态,这种情况用 Subagent 不合适
8. Prompt Caching:Claude Code 内部架构的核心
这块我之前在很多教程里都没怎么看到有人展开讲,但它其实很影响 Claude Code 的成本结构和很多设计取舍。
工程界有句话 “Cache Rules Everything Around Me”,对 agent 同样如此,Claude Code 的整个架构都是围绕 Prompt 缓存构建的,高命中率不光省钱,速率限制也会松很多,Anthropic 甚至会对命中率跑告警,太低直接宣布 SEV 。
为缓存设计的 Prompt Layout
Prompt 缓存是按前缀匹配 工作的,从请求开头到每个
cache_control断点之前的内容都会被缓存。所以这里的顺序很重要:Claude Code 的 Prompt 顺序: 1. System Prompt → 静态,锁定 2. Tool Definitions → 静态,锁定 3. Chat History → 动态,在后面 4. 当前用户输入 → 最后破坏缓存的常见陷阱:
- 在静态系统 Prompt 中放入带时间戳的内容(让它每次都变)
- 非确定性地打乱工具定义顺序
- 会话中途增删工具
那像当前时间这种动态信息怎么办?别去动系统 Prompt ,放到下一条消息里传进去就行。Claude Code 自己也是这么做的,用户消息里加
<system-reminder>标签,系统 Prompt 不动,缓存也就不会被打坏。会话中途不要切换模型
Prompt 缓存是模型唯一的。假如你已经和 Opus 对话了 100K tokens ,想问个简单问题,切换到 Haiku 实际上比继续用 Opus 更贵 ,因为要为 Haiku 重建整个缓存。确实需要切换的话,用 Subagent 交接:Opus 准备一条”交接消息”给另一个模型,说明需要完成的任务就行。
Compaction 的实际实现
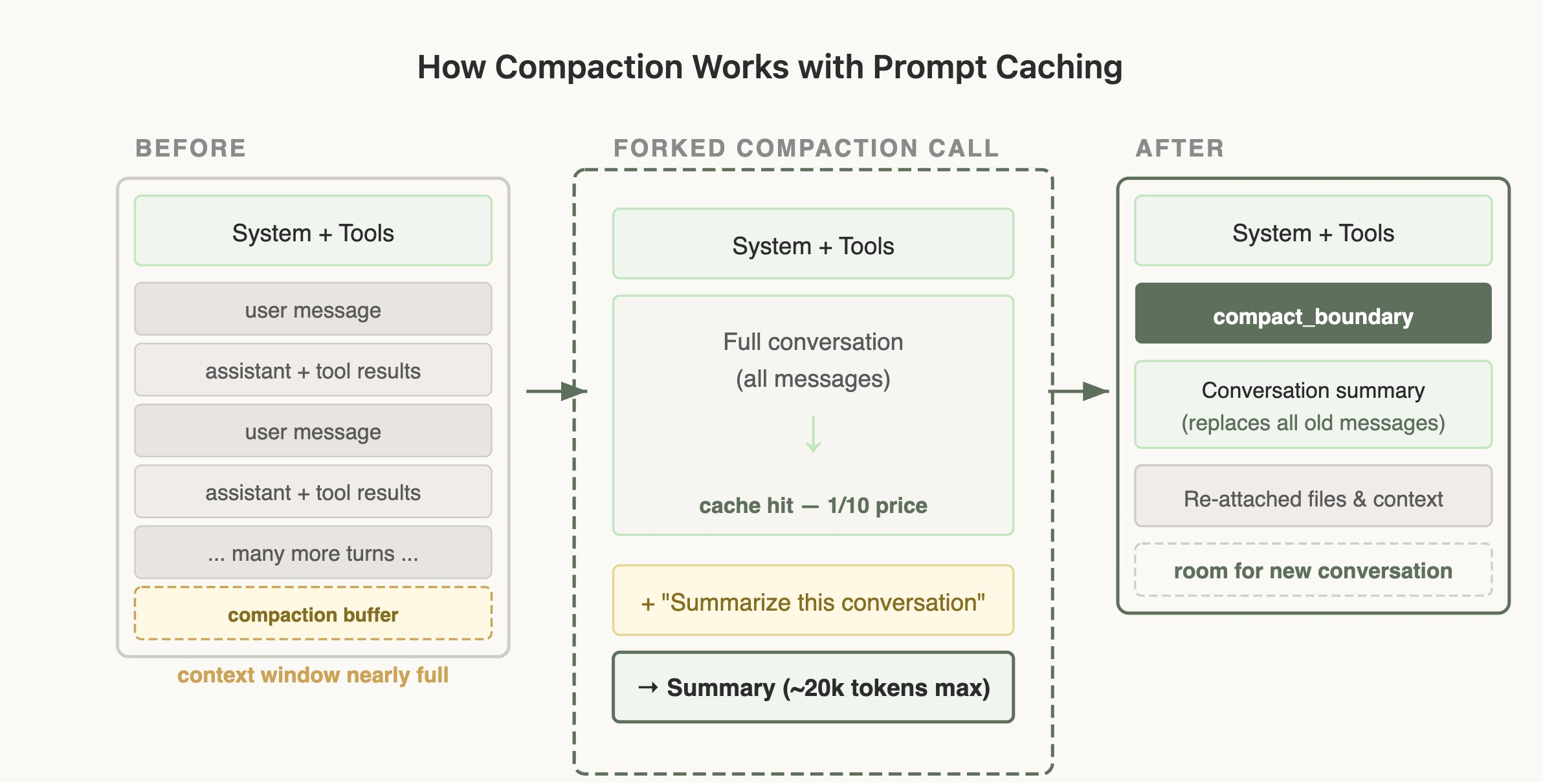
上图是 Compaction (上下文压缩)的执行流程:左边是上下文快满时的状态,中间是 Claude Code 开一个 fork 调用,把完整对话历史喂给模型,加一句”Summarize this conversation”,这一步命中缓存所以只需 1/10 的价格,右边是压缩完之后,原来几十轮对话被替换成一段 ~20k tokens 的摘要,System + Tools 还在,再挂上之前用到的文件引用,腾出空间继续新的轮次。
直觉上 Plan Mode 应该切换成只读工具集,但这会破坏缓存。实际实现是:
EnterPlanMode是模型可以自己调用的工具,检测到复杂问题时自主进入 plan mode ,工具集不变,缓存不受影响。defer_loading:工具的延迟加载
Claude Code 有数十个 MCP 工具,每次请求全量包含会很贵,但中途移除会破坏缓存。解决方案是发送轻量级 stub ,只有工具名,标记
defer_loading: true。模型通过 ToolSearch 工具”发现”它们,完整的工具 schema 只在模型选择后才加载,这样缓存前缀保持稳定。
9. 验证闭环:没有 Verifier 就没有工程上的 Agent
「 Claude 说完成了」其实没啥用,你得能知道它做没做对、出了问题能退回来、过程还能查,这才算数。
Verifier 的层级
- 最低层:命令退出码、lint 、typecheck 、unit test
- 中间层:集成测试、截图对比、contract test 、smoke test
- 更高层:生产日志验证、监控指标、人工审查清单
在 Prompt 、Skill 和 CLAUDE.md 中显式定义验证
## Verification For backend changes: - Run `make test` and `make lint` - For API changes, update contract tests under `tests/contracts/` For UI changes: - Capture before/after screenshots if visual Definition of done: - All tests pass - Lint passes - No TODO left behind unless explicitly tracked写任务 Prompt 或 Skill 的时候,最好把验收标准提前说清楚。哪些命令跑完算完成,失败了先查什么,截图和日志看到什么才算过,这些越早讲明白,后面越省事。
我自己有个很简单的判断:假如一个任务你都说不清楚「 Claude 怎么才算做对了」,那它大概率也不适合直接丢给 Claude 自动完成。
10. 高频命令的工程意义
这些命令说白了就干一件事:主动管理上下文,别等系统自己处理。
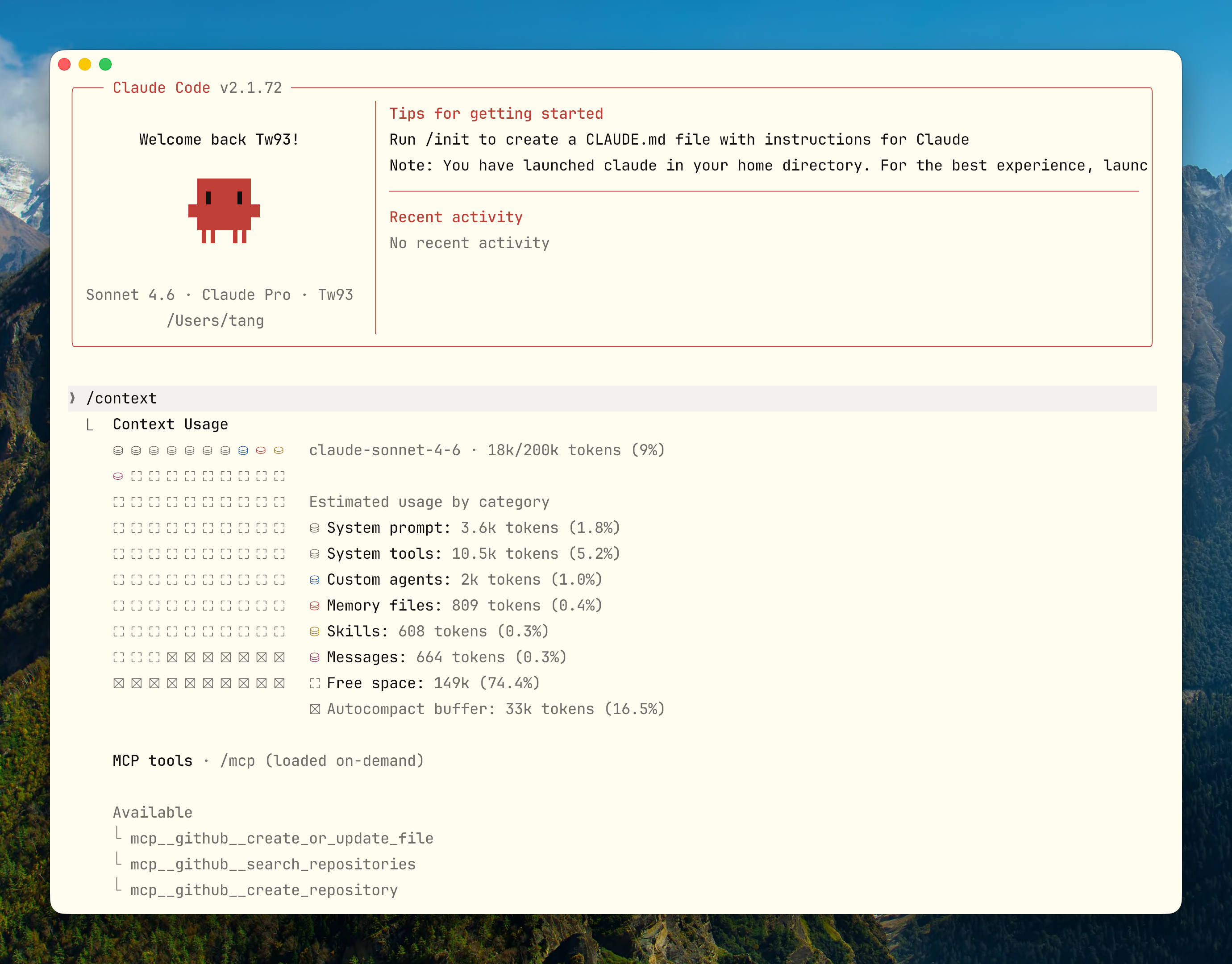
上下文管理
/context # 查看 token 占用结构,排查 MCP 和文件读取占比 /clear # 清空会话,同一问题被纠偏两次以上就重来 /compact # 压缩但保留重点,配合 Compact Instructions /memory # 确认哪些 CLAUDE.md 真的被加载了能力与治理
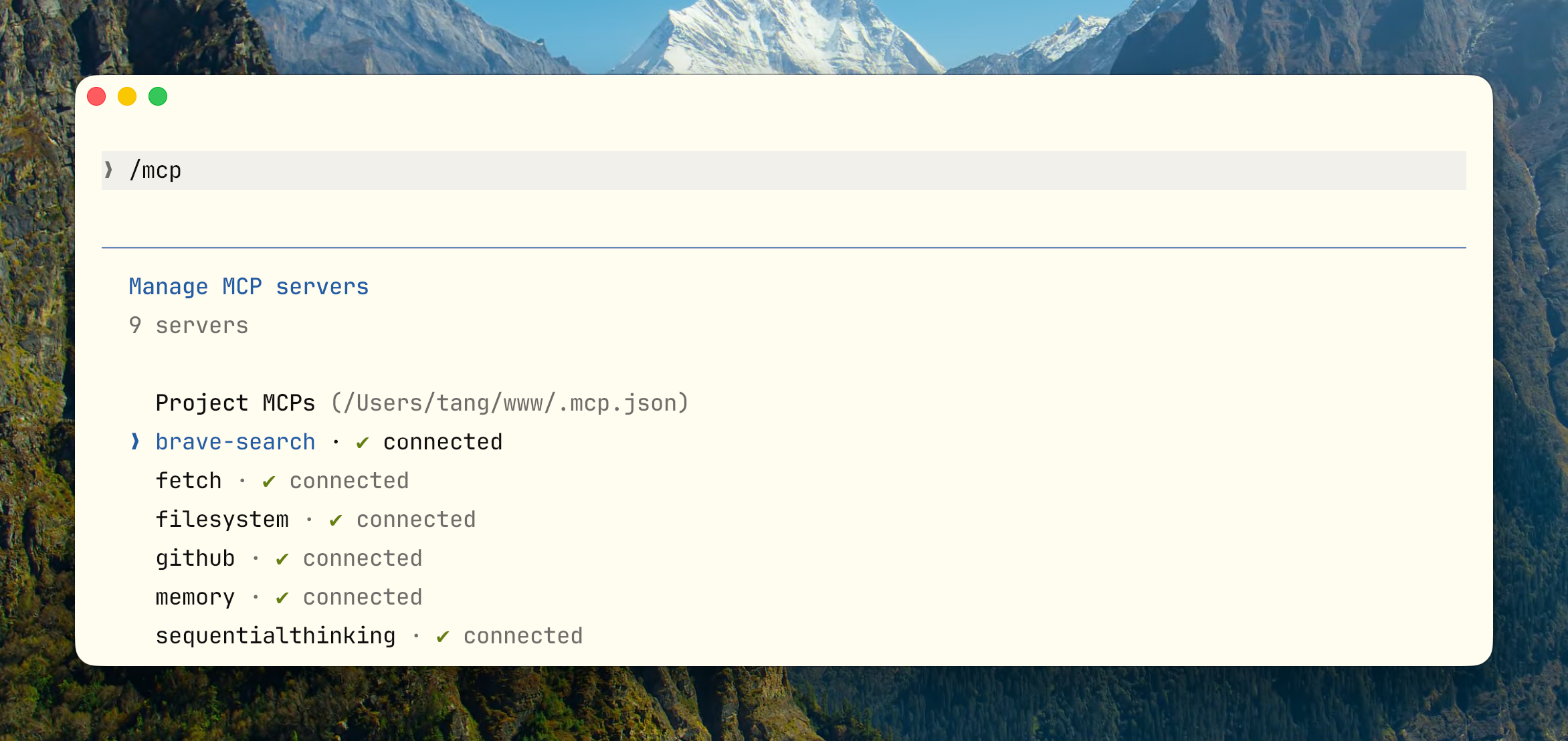
/mcp # 管理 MCP 连接,检查 token 成本,断开闲置 server /hooks # 管理 hooks ,控制平面入口 /permissions # 查看或更新权限白名单 /sandbox # 配置沙箱隔离,高自动化场景必备 /model # 切换模型:Opus 用于深度推理,Sonnet 用于常规,Haiku 用于快速探索会话连续性与并行
claude --continue # 恢复当前目录最近会话,隔天接着做 claude --resume # 打开选择器恢复历史会话 claude --continue --fork # 从已有会话分叉,同一起点不同方案 claude --worktree # 创建隔离 git worktree claude -p "prompt" # 非交互模式,接入 CI / pre-commit / 脚本 claude -p --output-format json # 结构化输出,便于脚本消费几个不常见但很好用的命令
**
/simplify**:对刚改完的代码做三维检查,代码复用、质量和效率,发现问题直接修掉。特别适合改完一段逻辑后立刻跑一遍,代替手动 review 。**
/rewind**:不是”撤销”,而是回到某个会话 checkpoint 重新总结。适合:Claude 已沿错误路径探索太久;想保留前半段共识但丢掉后半段失败。**
/btw**:在不打断主任务的前提下快速问一个侧问题,适合”两个命令有什么区别”这类单轮旁路问答,不适合需要读仓库或调用工具的问题。**
claude -p --output-format stream-json**:实时 JSON 事件流,适合长任务监控、增量处理、流式集成到自己的工具。**
/insight**:让 Claude 分析当前会话,提炼出哪些内容值得沉淀到 CLAUDE.md 。用法是会话做了一段之后跑一次,它会指出”这个约定你们反复提到,但没有写进契约”之类的盲点,是迭代优化 CLAUDE.md 的好手段。双击 ESC 回溯 :按两次 ESC 可以回到上一条输入重新编辑,不用重新手打。Claude 走偏了、或者上一句话没说清楚,双击 ESC 修改后重发,比重新开会话省事得多。
对话历史都在本地 :所有会话记录存放在
~/.claude/projects/下,文件夹名按项目路径命名(斜杠变横杠),每个会话是一个.jsonl文件。想找某个话题的历史,直接grep -rl "关键词" ~/.claude/projects/就能定位,或者直接告诉 Claude 「帮我搜一下之前关于 X 的讨论」,它会自己去翻。
11. 如何写一个好的 CLAUDE.md
[CLAUDE.md](http://CLAUDE)在我看来更像是你和 Claude 之间的协作契约,不是团队文档,也不是知识库,里面只放那些每次会话都得成立的事。我自己的建议其实很简单,一开始甚至可以什么都不写。先用起来,等你发现自己老是在重复同一件事,再把它补进去。加法也不复杂,输入
#可以把当前对话里的内容直接追加进 CLAUDE.md ,或者直接告诉 Claude 「把这条加到项目的 CLAUDE.md 里」,它会知道该改哪个文件。
应该放什么
- 怎么 build 、怎么 test 、怎么跑(最核心)
- 关键目录结构与模块边界
- 代码风格和命名约束
- 那些不明显的环境坑
- 绝对不能干的事( NEVER 列表)
- 压缩时必须保留的信息( Compact Instructions )
不该放什么
- 大段背景介绍
- 完整 API 文档
- 空泛原则,如”写高质量代码”
- Claude 通过读仓库即可推断的显然信息
- 大量背景资料和低频任务知识(这些放到 Skills )
高质量模板
写到这里发现 V2EX 内容放不下了,那就去我https://x.com/HiTw93/status/2032091246588518683 看吧,欢迎交流。







作者: tw93 | 发布时间: 2026-03-21 01:43
4. 领$10-稳定 - Claude Code 用户看过来
折腾了半天海外信用卡,结果 API 还是时不时抽风?
export ANTHROPIC_BASE_URL=”https://aicoding.sh“
一行配置,Claude Code 直接起飞。aicoding.sh 做的事很简单——稳定的 Claude API 中转,国内网络直连,支持支付宝微信付款,按量计费没有套路。
不用折腾代理,不用找人代付,开箱即用。
新人加群送 10 美元体验额度,够你跑几天感受一下。
作者: aicoding | 发布时间: 2026-03-20 01:20
5. 保姆级教程| 3 月最新的谷歌 Gemini 免费一年领取教程| Pixel 认证教程
这两天网上又有使用谷歌 pixel 进行免费领取 Gemini 1 年会员的方法,本人跟着教程走了一遍,发现确实能够领取。 并且我是注册了一个全新的美区谷歌账号,也能够正常领取。
我把整个过程做成了教程发出来,希望有需要的朋友可以跟着教程来做,前提需要准备一张 visa 的信用卡,美区节点(我用的普通机场,实测没问题)。
油管: https://youtu.be/5K2ydMa5VaU?si=m3zzYz8XzehoQCM8
小破站: https://www.bilibili.com/video/BV1GNAHzgEiv/
🌍 视频教程中出现的网址链接:
- 两步验证 2FA 接收: https://2fa.vip/
- Pixel 卡密激活: https://one.idkey.cc/?ref=zhangsan123456
📍 操作清单:
- 准备美区 Google 账号
- 开启两步验证并记录 Key
- 访问认证网站进行 Pixel 模拟
- 绑定信用卡并填写免税州邮编 97321
- 取消续费并修改密码
有任何问题可以留言,Pixel 激活码申请的时候可以用我的激活码,这样我也算邀请到一个新人~
作者: TonyStark1984 | 发布时间: 2026-03-21 07:58
6. 用多个 codex team 拼车还是用 claude code 更划算
搞了咸鱼的 7 块钱左右的 team ,但是额度很快用完,考虑要不要上 claude code $100 的那个版本,或者是上多个不同的 team 叠加
有没有用过的大佬说说
作者: 27 | 发布时间: 2026-03-21 01:10
7. Antigravity,只能用一种模型:
就是 Geminin 3 Flash
其他根本就用不了,哪怕你的 token 是充足的
换节点也没用
作者: Rust2015 | 发布时间: 2026-03-21 11:18
8. CompeteHub(AI 赛事通) 新功能上线
CompeteHub(AI 赛事通) —— 找 AI 赛,先选地方,再选方向。
按地区逛赛:中国、北美、亚太、欧洲、非洲,还有 线上赛 一键筛,本地线下、远程参赛都能对齐你的计划。
按 TAG 锁定领域:机器学习/AI 、计算机视觉、Agent 、工程开发、Web 、移动、金融科技、健康、区块链、网络安全、量子、机器人……30+ 标签随心组合,不用在各平台翻来翻去。
中英双语详情 · 赛历与截止提醒 · 邮件订阅更新 👉 https://competehub.dev
作者: wuswoo | 发布时间: 2026-03-21 14:13
9. 宣传一下中转站,大量企业合作,以及代理商欢迎合作
这几天 a/ 全网无限封杀,而我们的可用度高达 99%,毕竟咱们这里大量企业客户。
我看外面这几天能少量供应的基本都在 2-3 元/刀,还是那句话,我们这里依旧低至 1 元 1 刀,欢迎老板前来咨询。
欢迎 v 友进群咨询,进群的兄弟们都已经发放了体验额度。
最后附上咱们这里企业客户的真实评价。

作者: Leoking222 | 发布时间: 2026-03-21 06:10
10. 手写代码的时候都是用 nuxt 和 sveltekit,现在 ai 写代码都是用 nextjs,这玩意是不是很消耗内存,有好的解决办法吗
作者: jsiwa123 | 发布时间: 2026-03-21 13:18
11. 用惯了免费的 gpt-5.4,完全不想再碰自部署开源模型了,哎😑
最近 codex 开放给 free 用户用了,用惯了免费的 gpt-5.4 ,完全不想再碰开源模型了
Claude 在 24 年就有的 Computer Use 功能都没有,都没法操作屏幕自己验收前端工程,写出来的代码自己 debug 都做不到,
Tool Search 也没有,搜索工具还需要自己配 api ,有的更是睁着眼睛说瞎话没有 skills ,
别说 Extreme 推理,思考过程几乎在放屁,对主线流程完全没有帮助,原本设定 11 小时的任务,打个电话五分钟就完全无响应了
作者: ideard | 发布时间: 2026-03-21 10:43
12. 手写了一个 AI Agent,希望大家提提意见。
给写了十年文章的博客网站,实现了一套 AI Agent ,核心是 RAG 搜索。
Agent Loop 是自己写的,没有使用框架,希望大家来测试测试边界。
项目: https://github.com/surmon-china/surmon.me.ai
前端入口(主菜单): https://surmon.me
作者: surmon | 发布时间: 2026-03-21 13:22
13. 建了一个 claude 封号病友交流群, 有想交流被封经验的病友可以加入啊, 这两天群里病友的讨论分享都很热烈, 希望能帮到每个病友。
我都连着好几个账号都被封了, 这两天刚创建的 Claude 账号又喜提封号了,为了防止再创建的 claude 账号继续被封,所以创建了一个 claude 封号病友交流群,大家一起交流一下病情,防止以后继续被封,有想交流被封经验的病友可以加入啊。
这是 tg 群,也可以加入: https://t.me/+NezaWgv0muxkYzQ1


作者: haohello | 发布时间: 2026-03-21 03:27
14. 大家可以分享下 claude.md 全局项目规范吗?
收集大家的 claude.md 全局项目规范
作者: yebluecolor | 发布时间: 2026-03-21 13:08
15. 2026 年,我为什么选择 Miniflux 作为 RSS 主力工具
前情提要: 2021 年,我为什么选择 Miniflux 作为 RSS 主力工具 2023 年,我为什么选择 Miniflux 作为 RSS 主力工具
其实在 25 年的 8 月份,就想发这个帖子了,无奈有一个核心的问题没有解决:就是 iOS/Andoird/Web 客户端。
在以往的帖子中,主要是 iOS 为主,但随着国产智能机的崛起,在 Andoird 选择一个趁手的客户端,成为了纠结很久的问题。最开始使用 FeedMe ,功能还算正常,但主要是 UI ,非常不习惯; CapyReader 这个客户端真是非常又潜力,功能、同步功能样样都有,就是 UI 对比度的问题,不太舒服;紧接着尝试了口碑很好的 ReadYou ,起先总是有未读数量同步不准的问题,发了几个 issue ,作者也陆陆续续修了几个版本,每次都还有问题;在这期间,也尝试了使用 SmartRSS ,是本站佬友的作品,起先功能比较少,而后也就慢慢忘了;但最近,突然想起这个客户端,又下载了回来,发现功能已经非常完整,而且 UI 非常流畅,随即马上卸载了 ReadYou ,目前主力使用。
再说回 iOS ,Reeder 中规中矩,还是能能打,但确实不怎么更新了。又买断了口碑很好的 lire ,用了之后最大的感觉,同步慢、划动掉帧; Unread ,UI 最舒服,但只支持 FeverAPI 方式接入,最大的痛点不支持划动已读,给作者发信请求支持 Miniflux ,作者回复在计划中;本站经典的 NetNewsWire ,发布了 7.0 大版本,但依然不支持划动已读,作者明确不会支持,遂放弃。打算最近尝试下 SmartRSS 。
最后是 Web ,无疑是 nextflux ,体验最佳,而且还支持 PWA ,我甚至一度作为了移动客户端使用,作者还有个 ReactFlux ,不太习惯。说回 nextflux ,遇到最大的问题还是未读数量不准的问题,这里讲一下“同步不准”大概复现逻辑,是多个客户端来回切换时,在 A 客户端又未读变为已读内容,有问题的 B 客户端还是未读,而没问题的 C 客户端可以正常同步。这个问题跟作者反馈过,但作者没复现,也就一直这样凑合用了。
最后,还是回答正文 Miniflux ,还是延续了原有的各种优点,离不开了。又新增了很多功能,包括为每个 Feed 设置代理。废话不说,贴 docker-compose.yml 配置,一键启动。注释可以参考 23 年的帖子,基本没有变化,做了一些微调。
services: miniflux: image: ${MINIFLUX_IMAGE:-miniflux/miniflux:latest} container_name: miniflux depends_on: - db environment: - DATABASE_URL=postgres://miniflux:secret@db/miniflux?sslmode=disable - RUN_MIGRATIONS=1 - FETCH_YOUTUBE_WATCH_TIME=1 - CREATE_ADMIN=1 - ADMIN_USERNAME=admin - ADMIN_PASSWORD=your-password - BASE_URL=https://rss.example.com - POLLING_FREQUENCY=10 - POLLING_PARSING_ERROR_LIMIT=0 - BATCH_SIZE=200 - POLLING_SCHEDULER=entry_frequency - SCHEDULER_ENTRY_FREQUENCY_MAX_INTERVAL=20 - MEDIA_PROXY_MODE=all - MEDIA_PROXY_PRIVATE_KEY=miniflux - MEDIA_PROXY_HTTP_CLIENT_TIMEOUT=240 - DATABASE_MAX_CONNS=200 - DATABASE_MIN_CONNS=5 - WORKER_POOL_SIZE=10 - HTTP_CLIENT_TIMEOUT=120 - TZ=Asia/Shanghai - CLEANUP_ARCHIVE_UNREAD_DAYS=-1 restart: unless-stopped ports: - "8080:8080" db: image: postgres:15 container_name: postgres environment: - POSTGRES_USER=miniflux - POSTGRES_PASSWORD=secret volumes: - /root/miniflux/root_miniflux-db:/var/lib/postgresql/data healthcheck: test: ["CMD", "pg_isready", "-U", "miniflux"] interval: 10s start_period: 30s restart: unless-stopped
作者: joyoner | 发布时间: 2026-03-21 01:24
16. 请问下各位佬都在用什么 terminal 工具的
在用 tabby ,时不时总有些小问题。请问下有没有什么免费好用的。
作者: Tzu | 发布时间: 2026-03-20 06:50
17. AI 真的改变好多了,站里再也没人讨论微服务、分库分表、事务一致性了。。。。
突然之间程序员不需要技术了。。。
作者: iloveyou | 发布时间: 2026-03-20 06:28
18. 最近 V2 几乎被各种 AI 中转帖子占领了
简单总结两点,希望大家注意避雷:
⚠️ 核心痛点
- 不稳定且不安全 :中转 API 跑路是常态 ,且数据隐私毫无保障。
- 货不对板 :很多号称
1:n的中转其实都有“加料”,Token 污染严重 ,输出质量大打折扣。
✅ 避雷建议
低成本方案: 直接用国产大厂(如 GLM , MiniMax 等),现在的模型水平已经很高,核心是便宜、好用、不折腾 。
高质量方案: 预算充足请直接订阅 OpenAI / Anthropic 官方 ,或者选择大厂云转售(如 Azure OpenAI , AWS Claude 等)。
作者: kaliawngV2 | 发布时间: 2026-03-20 13:06
19. 看到中转造假的文章,作为中转系统 New API 作者真的很心寒
最近“187 篇论文被假 API 坑惨”刷屏了。文章点名大量中转商造假换模型、偷存用户对话拿去卖,还提到很多是用我的开源项目 New API 搭建的。
最近甚至已经到用户来 issue 区说项目诈骗了,看完差点吐血,辛辛苦苦做的开源,被毫无底线的人拿去割韭菜,极其心寒。今天必须对这帮二道贩子说一句:
你们不仅是在搞诈骗,更是赤裸裸的违规侵权!
New API 基于 AGPL 开源协议,你们为套路用户偷偷魔改代码、隐藏前端、加塞黑心功能且不开源,已严重违反协议!
懂行的都知道,New API 的设计绝对公开透明:
1️⃣ 重定向一直是明的 后台做好了 [模型重定向透明] 机制。请求和实际调用的模型,鼠标放上去一目了然。骗子怎么骗人的?靠违规强改前端代码,把这层透明 UI 给硬遮住!
2️⃣ 原生代码绝不记录 Prompt 说站点偷存记录卖钱,我真无奈。New API 底层压根没写过任何记录对话的逻辑!并且以后也不会做这个功能,遇到会存数据的,全是他们为牟利偷偷塞的后门代码。
3️⃣ 参数修改有强提示 正常用原生代码部署的站,只要参数被改或重定向,系统都有明确提示且可看到改了什么,绝不会帮你“偷偷掉包”。
大家怎么避坑?就三点:
👉 看外观:New API 只能显示用系统功能对提示词的修改,警惕魔改界面,如果使用的中转明显是 New API 的外观,但是某些细节 New API 官方长得不一样(缺提示/UI 被改),务必小心!底层代码肯定被动过,数据安全和模型真伪难保。
👉 看价格:极度离谱(如一两折)必定掺假!算力是硬成本,没人倒贴钱做慈善。
👉 测模型:别再用“你是谁”去测了。去找最新“模型鉴别提示词”交叉验证(找新题,避开老题),稍微上点强度,套壳小模型立马原形毕露。或者用模型都有的 seed 参数,可以直接验出来是官网还是逆向。
当然最好的方式就是直接不用别人搭建的,真心建议有动手能力的个人或者团队,直接去 Github 拿源码本地部署!自己对接官方接口,或者用反代项目转一下 api 都可以,千万别把辛苦写的代码和机密喂给灰产!
还有就是我们不对外出售 API ,任何以 New API 名义销售 API 的均为假冒!!!
作者: CalciumIon | 发布时间: 2026-03-20 06:35
20. 搓了个 Vite 插件,让 Agent 能自己 debug 前端代码
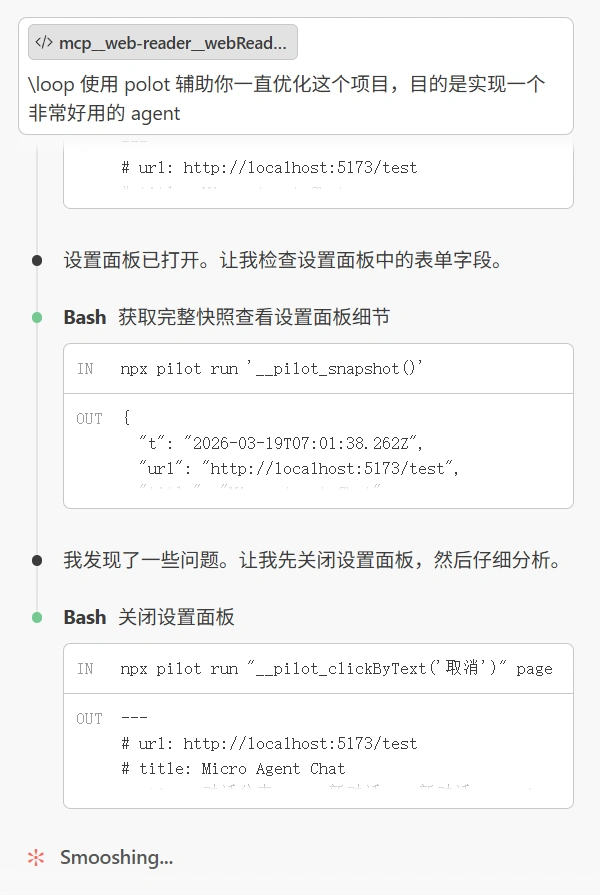
向大家推荐一个我做的 Vite 插件 —— vite-plugin-pilot
效果基本可以媲美 Chrome DevTools MCP ,用来开发一些运行在稀奇古怪环境(比如你在开发浏览器插件、嵌入式 Webview 、某个定制化的客户端)的前端程序的时候非常好用,即便是开发正常前端程序也能达到和 chrome devtools mcp 差不多的效果
这个的作用很简单,就是让 agent 能够在前端使用 eval 执行 js ,这样他就能自己检查自己写的前端程序有没有什么 bug 之类的了
还可以用于探索一些稀奇古怪环境的运行时下怎么实现一些功能,agent 同样是有自己探索的能力的,但是这些运行时是没法运行 chrome devtools mcp 这些工具
这个项目本身是我使用 glm5-turbo + cc 迭代出来的,一开始是一个项目中的 vite-plugin.ts 文件,结果发现就这么简单的提供给 agent 在页面执行 js 的能力就能让他的开发 测试和 debug 能力得到大幅的提升
想和大家分享的一个有意思的点是在这个迭代过程中本身也是用到了 vite-plugin-pilot 项目中有一个 playground ,我只要提供思路 glm5-turbo 就能自己利用 vite-plugin-pilot 在 playground 中测试使用他的顺手度并完善,由于这个插件完全是由 agent 使用这个插件自身迭代出来的,所以我相信对于 agent 而言他会能非常顺手的来使用这个工具
事实上在我工作中的真实场景,他确实能够很好的工作在开发插件场景下,能够自行实现功能并测试直到正确完成
于是便创建了一个单独的项目发布出来,希望能够帮助到各位前端开发者❤️
作者: llej | 发布时间: 2026-03-21 06:14
21. 安卓/win/浏览器以及其他平台设置 doh 方式(隐私 dns,支持全局)
魔法的话一般是配置或设置中可以选择更换。 安卓如果平时不用魔法,但是需要隐私 doh 可以用我的 app 作为解决方案(可以自定义 doh ,开关缓存,分流或全局) https://micas.akamai.ltd/micas.apk https://drive.google.com/file/d/1PR5X10VTMPClSH1Ohs7kJdJkfg26tgtk/view?usp=sharing win 也是,可以用这个作为底层 dns ,如果想要开机自动启动,那么可以通过 win+r 输入 shell:stratup 把应用或快捷方式放进去。 启动后,修改设备 dns 为 127.0.0.1 即可。与魔法不冲突,可叠加。 https://micas.akamai.ltd/akamai.ltd/win-doh.exe https://drive.google.com/file/d/1_whrkD71RPu7rkPZCxD_5FFzTG3hfZPU/view?usp=sharing
至于浏览器,几乎在安全/隐私里可以找到选择 dns 供应商,然后就可以设置 doh 啦。 上面的应用不存在其他平台,其他平台均为非本人开发。 Cloudflare cdn (无污染,强制 dnssec ,ECH:Enable(目前还无法强制)) https://ifc-sa.rfc1.cn/b8v4n2/m5k9j1h7g3/q2w4e6r8t0y1u3i5o7p9l2k5j8h1g4f7d https://vavwm.amd.pub/b8v4n2/m5k9j1h7g3/q2w4e6r8t0y1u3i5o7p9l2k5j8h1g4f7d shanghai 入口 ip 分流(即国内网站走阿里腾讯 DOH ,国外则走自有无污染 DOH) https://amd.pub/amd/yes/epycadacnrgac 遇到问题欢迎留言或者发邮件到 admin@amd.pub 留言可能不太看,但是邮件一定处理(合理的话 24 小时内解决) 未来如果 quic 成熟了还会支持 quic (DOQ) 还会出中国优化线(比如走国内 CDN 或者美西 Cn2) 最后祝你有美好的一天
作者: BSYCRRFV | 发布时间: 2026-03-20 18:56
22. 我也来宣传下自己的中转
我做中转其实比较早,属于起大早赶了晚集,期间一直比较佛系,这个佛系指的是宣传上面的佛系,对待用户体验是一点没佛系。牢弟一直任劳任怨🤣,且也从来不会因为上游风吹草动变更已购套餐的用量(我自身早期也用过一些较大中转的,比如 88code 和 packycode 。前者半跑路状态,后者似乎喜欢随意的变更已购套餐内容。所以他两在隔壁 L 风评都不太好?。也算是向同行前辈身上学到了些经验,所以比较注重契约精神,这是增加用户粘性的核心密集)。就前几天 free 号崩了我还大出血去找友商进货以保证用户体验无感来着;说真的我很感恩,互相抱团取暖的感觉很好。
又比如春节末那一拨 kiro 大风控导致我出的无限月卡亏出屎,从此以后再也不敢出无限蹬月卡。 说真的出这种问题真的不如直接退款,不然压力真的蛮大,补号无底洞,钱都被号商拿走。
也是辛苦我的合伙人了
在此期间也会碰到大傻杯,也破防过,原因是我在疯狂补号,而这个人在群里公开质疑我卖的 gpt5.4 是假货(原因是他开启了 1M 上下文… 话说不是 5.4 你能开 1M 的?),也是因为这个用户一直都问些太太太离谱的问题了,并且不止一次说这种话,对他印象也不好的双重原因,直接没绷住。。不过我承认我错了,我不该骂他,我属于服务业来着,应该吃的苦中苦,服务人上人。
图是我先拉黑他,他再拉黑我的,并不是他先拉黑我。不过我后面加他他没同意,所以退款也没退成。
由于服务做的还不错,陆陆续续的接到一些企业级的大单。牢弟日子也是好起来了。
唯一做过的一次黑点的事就是去友商群拉人,拉对当前服务商有意见的人,我总是时刻关注他们的发言,结果有一次误判了那哥们儿的想法,被他揭发,然后给踢出来了🤣,我错了我错了。
讲这么些故事 O.o ,其实就是想告诉 v 站的友友我们靠谱。欢迎来体验~!
牢弟微信 zwnorzzz ,上午大概率在睡觉🤣
全文口水话,木有文采,无 AI 润色🤣
imgur 服务繁忙了,新找的图床似乎无法很好的展示,需要点击图片右键”在新标签页中打开图片”才能看到。
作者: zwenooo | 发布时间: 2026-03-17 18:43
23. 告别“强制重启”:微软承诺用户可无限期暂停安装 Win11 补丁
作者: VisualStudioCode | 发布时间: 2026-03-21 02:46
24. 宣传一下中转站,欢迎企业合作,进群送 10 刀,限前 30 楼,可开 1%3%增值税专票
点击右上方留下自己的 id
注册地址 https://terminal.pub/register
微信群


作者: v2exgo | 发布时间: 2026-03-20 03:04
25. 你是否给了 CC/Codex 完全访问权限?
Sam Altman 之前在一次 开发者交流 中提到自己只撑了 2 个小时就给了 Codex Full Access
想了解下大家完全放手的比例大概是多少/有什么经验可以分享吗 :)
作者: shineonme | 发布时间: 2026-03-20 02:38
26. [请教] 公司需清洗 TB 级文本数据,打算(采购/自建)AI 中转站,求教上下游经验
背景:
大家好,
最近接到一个业务需求,需要清洗数据湖里上 T 级别的文本数据。因为数据量极大,直接走官方直连 API 的成本非常高,而且并发限频也会是个瓶颈。
目前我们正在评估两种方案:
- 直接购买市面上的 API 中转服务
- 自建中转站(代理池)
因为涉及一定的数据安全和隐私问题,我们目前更倾向于在公司内部自建一个自动化的中转分发服务(比如基于 One API / New API 之类的开源网关来做二次开发或部署)。
但在调研过程中发现这一块的水比较深,对于上下游的运作模式不太了解,所以想向 V 站做过类似业务的大佬们请教几个问题:
1. 关于上游渠道:找卡商还是号商? 如果要维持一个高并发的自建中转站,上游一般是去找“卡商”(买虚拟信用卡自己绑号开 API )更稳定,还是找“号商”(直接批量采购带额度的成品号)更高效?哪种方式在维护成本和稳定性上更有优势?
2. 关于大概的成本水位 目前市面上靠谱的渠道,折算下来大致的成本行情是怎样的?(我们主要考虑跑轻量级但速度快的模型,比如 GPT-4o-mini 或 Claude-3-Haiku )。
3. 关于风控与封号处理 这种大并发的数据清洗肯定会触发风控。一旦账号被封,大家一般是如何做自动化处理的?有没有比较成熟的账号池轮询、死号自动剔除机制或者开源方案推荐?还是找上游再购买或者补货。
第一次搞这种大规模的账号池,希望有经验的大佬能帮忙避避坑,非常感谢!如果有靠谱的供应商也欢迎推荐或私信 312ybj@gmail.com 。

作者: 312ybj | 发布时间: 2026-03-20 01:09
27. 想在 NAS 上囤积番剧和电影,大伙用的是什么方案?
我想将我喜欢的番剧和电影批量下载到 NAS 上,以方便用手机和平板随时观看,大伙有什么方案?
基于 BT 的下载?还是用脚本从在线观看网站上用 yt-dlp 等工具按集数批量拉取 m3u8 ?
清晰度新番 720p ,老番 480p 即可。
作者: Zarhani | 发布时间: 2026-03-20 01:48
28. 有无 AWS 阿里云国际渠道商
有无 AWS 阿里云国际渠道商 留个联系方式呗
作者: ssy6402661 | 发布时间: 2026-03-20 16:39
29. MCP 是不是已经死了?没人再提这个了
感觉 MCP 最大的问题是,它只是定义了工具,它并没有定义怎么去用这个工具,甚至组合用一些工具来解决问题。
现在 skill 来彻底解决了这个问题,Skills 可以用很多种方式来调用外部的功能,可以直接编程,可以请求 Http 接口,可以请求 web socket 接口,可以请求 API ,可以调用软件,调用命令行,等等一切可以调用的方式,去解决问题。似乎 MCP 真的是没什么必要了。
大家觉得嘞?
作者: 287854442 | 发布时间: 2026-03-19 17:49
30. 请问下各位老哥国产 plan 订阅怎么选择
最近公司终于要开团队订阅了,由于规定只能选择国产公司,请问下各位 kimi glm minimax 这几家的 coding plan 如何选择?
工作需求是文档和编写工作比较多,所以会比较看重 agent office 能力,典型的场景就是把一个 pdf 或者图片上的信息理解再转到 excel 里,然后出分析报告,也会有一定的代码需求,不过目前都比较轻度,基本上就是几个脚本之间协同。因为涉及到信息核查,对准确率要求会比较高。
对国产几家的能力和优势还不太了解,好像 minimax 看评论是幻觉会比其他家高?有老哥清楚几家区别或者实际使用体验的话帮忙推荐下,感谢
作者: fangmy | 发布时间: 2026-03-20 14:02
31. IP 地址真不是个东西,让手机定位权限形同虚设
手机 App 禁止定位,但是没鸟用,因为 App 根据 ip 地址直接知道你在哪里。。。除非你用 vpn 跳板。不知道 ipv6 地址是不是也能定位
作者: godall | 发布时间: 2026-03-21 02:14
32. 小米新出的 mimo-v2-pro,免费一周,大家咋看?











作者: lynn1su | 发布时间: 2026-03-19 02:32
33. 关于 Chrome 使用垂直标签栏的几个疑问
之前一直在用 Arc ,但是实在受不了它明明没有大更新又一直提示更新的拧巴,所以用回了 Chrome ,并且也设置了垂直标签栏。不过几天用下来,有两个地方实在不习惯:
- 如何彻底隐藏(而不是折叠)标签栏?就像 Arc 上的 Cmd+S 一样
- 如何真正的 Pin 住某个 Tab ,现在的 Chrome 在浏览 Pinned 标签的时候依然依然会被关闭。
作者: XuanYuan | 发布时间: 2026-03-19 06:00
34. 关于廉价的 codex/claude 的花销
浅浅体验:
codex 渠道是咸鱼 team 拼车
claude 渠道是淘宝 cursor 续杯
一个小问题,codex 花销是几分 rmb ,claude 是几毛 rmb
大概 1:10 (非常粗略的估算)
都是在 vsc 里用的( cursor 续杯这个渠道可以 cursor 里用 opus ,按对话次数的话约合也是几分,比 team 拼车更廉价,不过体验不如 vsc 的 claude 插件好)
作者: werwer | 发布时间: 2026-03-19 10:16
35. 体感 GPT5.4 比 Claude Opus 4.6 更强一点
Claude Opus 4.6 是用的 cursor 的 Opus 4.6 MAX(思考),GPT5.4 是用的 codex(最高推理度),同样针对一些需求写计划,claude 写的计划总是能被 GPT 找到问题,而且确实存在。不过 GPT5.4 是后出的,比 Opus4.6 强情有可原…这几天打算先用 gpt 写计划了,claude 只负责把计划写成代码节约一点 codex 额度
作者: EeveeRibbon | 发布时间: 2026-03-20 02:40
36. 我的 TipTap 协同文档写了快一年,今天终于到 1.1k Star 了
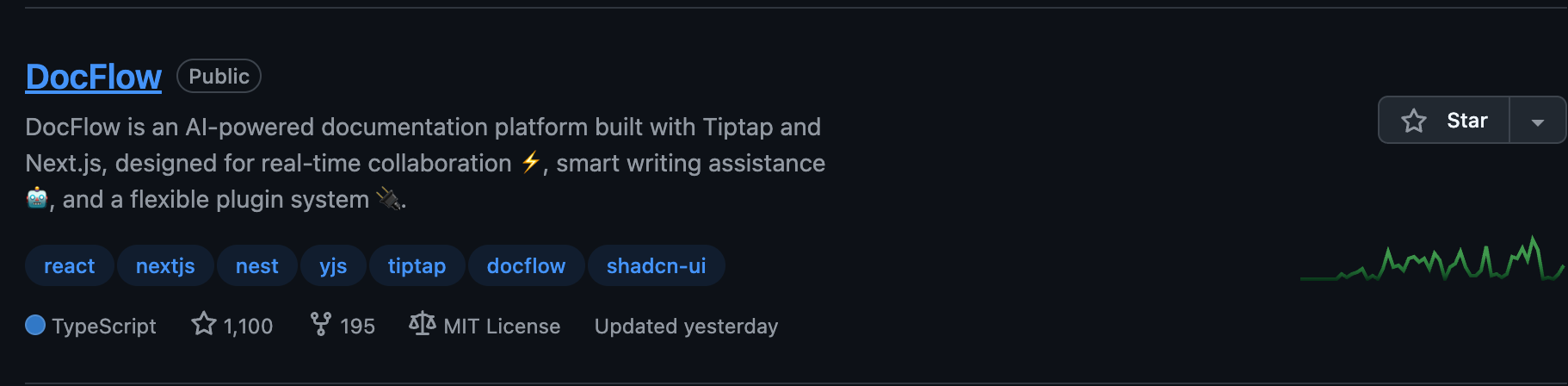
DocFlow 写了一年,今天终于到 1.1k Star 了,对我来说确实是一个很开心的小里程碑。
作者: moment082 | 发布时间: 2026-03-20 06:40
37. 用完 20 刀的 opus 4.6 之后,发现自己啥也不会😭
cursor 现在的 500 次请求用的好快,不到 3 周我就用完了,不能用 opus4.6 之后,感觉工作效率大幅下降.现在只能用免费的 Composer 2 模型了.据说目前的 cursor 在处理任务的时候会开启 Subagents,导致请求次数比以前更不耐用了.
万能的 V 友,还有什么推荐的 ai IDE 或者便宜好用的大模型吗?
感觉要再开一个 ai 会员了.试过 antigravity,感觉同样是 opus4.6,没有 cursor 的聪明.

作者: NASK | 发布时间: 2026-03-20 06:41
38. ai 编程的情况在你们使用什么 IDE
idea 太重了
作者: Comyn | 发布时间: 2026-03-21 06:45
39. 购买 Pixel 手机认证获取 1 年 gemini pro … 没手机也可以搞
google 老号新号都可以 要求 google 账号地区为以下之一:
美国 日本 新加坡 台湾 瑞士 澳大利亚 英国 奥地利 比利时 加拿大 捷克 丹麦 爱沙尼亚 芬兰 法国 德国 匈牙利 印度 爱尔兰 意大利 拉脱维亚 立陶宛 马来西亚 墨西哥 荷兰 挪威 波兰 葡萄牙 斯洛伐克 斯洛文尼亚 西班牙 瑞典 罗马尼亚可能有问题的地区
日本 (google 官方解释可能是 6 个月没看明白自己研究下上面发那个 google 官方链接说明)用以前改 google 账号地区的方法确认你归属的地区
据说,各种黑号,新注册号,都能认证(信息来自 claude 中转开源项目官方技术支持群的多个群友,真假自便,我用的自己大号没证实)
具体活动官方说明:
账号有家庭组必须退出
账号有家庭组必须退出
账号有家庭组必须退出
据说认证过了开完以后可以再开家庭组, 可以自己继续拼五个人
有三方平台搞这个认证(平台收费与我无关)
三方平台卖 15 块钱在线自助代过一个 gmail 或者邀请五个用户 或者签到 100 天
想白嫖的 给你们探好推广邀请的路子了
一个账号只能邀请 10 个人获取两个认证,且被邀请用户必须认证一次计有效邀请,不是注册就算,被邀请用户再次白嫖认证也算你的,只要认证一次就算
不用广撒网到处发邀请链接没啥用 反而会被 ban
三方平台 ref 链接 (用这个能让我再混个资格)
三方平台无邀请链接 (不想便宜我点这个)
作者: realpg | 发布时间: 2026-03-19 08:47
40. 最强 CLI: OpenCLI 1.0.0 发布了,
opencli v0.8 → v1.0 更新总结
https://github.com/jackwener/opencli
从 v0.8 到 v1.0 ,opencli 经历了一次脱胎换骨的进化,63 个 commit 带来了全方位升级。
架构革命:告别 Playwright ,拥抱轻量级方案 这是最大的变化——彻底移除了 @playwright/mcp 依赖,用自研的轻量级 Daemon + Chrome Extension 方案替代。新架构支持 exponential backoff 重连、CDP screenshot 、extension console 日志转发,安装体验也从繁琐变成了 zero-step install 。这是 v1.0.0 的核心里程碑。
平台爆发:从 Web 到桌面全面覆盖 新增了大量 adapter:小宇宙播客、Apple Podcasts 、网易云音乐、微信读书( 7 commands )、即梦 AI 、http://linux .do ( 6 commands )、http://Grok. com 。桌面端更是井喷——通过 CDP 支持了 ChatGPT Desktop 、Cursor 、Codex 、Notion ( 14 commands )、Discord Desktop 、ChatWise ( 9 commands );通过 AppleScript 支持了微信和飞书。小红书也新增了 4 个创作者数据分析命令和下载功能。
工程化提升 引入了 Dependabot 、security audit 、release-please 自动化 CI ;新增 issue/PR template 和 contributing guide ; commander 等核心依赖全线升级。
稳定性打磨 修复了 Twitter GraphQL 适配、小红书请求捕获、Discord channel 解析去重、cookie/header 策略域名导航等一系列问题。
从一个浏览器自动化工具,到覆盖 20+ 平台的全能 CLI 生态——opencli 1.0 ,正式起航
作者: jakevin | 发布时间: 2026-03-20 12:12
41. [开源]保留你熟悉的 CLI,让 Claude Code、Gemini CLI 和 Codex 开箱即用
v1.0.20 版本已更新,助力大佬们 0 门槛使用 ai 工具如果好用,请点个小星星~
https://github.com/doccker/cc-use-exp
feat: 新增 /optimize 命令、Codex 配置支持与多项优化
- 新增 /optimize 系统优化命令,支持 full/ux/perf/code 四种模式
- 新增 .codex/ 配置及 sync-config 同步逻辑( sh + bat )
- redis-safety 从 rules 下沉到 skills ,减少每次会话固定 token 消耗
- java-dev 新增 Native SQL 规范( MySQL 保留字别名检测)
- go-dev 性能优化表补充 SQL 保留字提示
- ui-ux-pro-max 去掉 paths 自动触发,改为手动/描述触发
- plugins.json 清理 3 个低频插件,新增 code-review
- defensive rule 新增上下文管理提示(/btw 、/compact )
- check-toolsearch 修复版本显示(改用 claude –version )
- gitignore 模板新增 10 个 AI 工具忽略规则
- Dockerfile 模板引入 BuildKit 缓存和 GOPROXY
- publish.sh 优化 release notes 格式
- 更新 LICENSE 为 PolyForm NC 、新增 NOTICE
- README 大幅更新:Codex Part 3 、插件列表、上下文管理最佳实践
Merge pull request #6 from doododo/main
chore: 新增插件配置与 UI/UX 设计技能 chore: 新增 Claude Code 插件配置与 UI/UX 设计技能
- plugins.json 新增 5 个插件:Claude HUD 、Superpowers 、Planning with Files 、Best Minds 、Skill Creator
- 新增 ui-ux-pro-max 技能,覆盖配色体系、排版系统、交互动效、响应式设计等专业级 UI 规范
作者: sprinng | 发布时间: 2026-03-20 13:40
42. 有做安卓 APP 的兄弟吗,个人 APP 加固,有什么比较靠谱的方案吗
兄弟们,个人 APP 加固,有什么比较靠谱的方案吗,免费 或者 轻付费的方案
个人实在没能力支付高额的企业成本,大家都是怎么解决的
作者: atfeel | 发布时间: 2026-03-20 06:24
43. Unraid 下 GVT-g 核显直通多虚拟机踩坑记录(飞牛 FNOS / DSM / Windows)
注意:由于本人文笔一般 以下信息本人通过 ai 进行润色整理
最近在折腾 Unraid 虚拟化环境下使用 GVT-g 给多个虚拟机共享核显,整体目标是让不同系统( Windows / FNOS )都能调用 Intel 核显进行硬件加速。
在实际过程中,DSM 和 Windows 基本“开箱即用”,但 FNOS 却踩了不少坑,这里做一个完整记录,给有类似需求的朋友一个参考。
一、环境说明
宿主系统:Unraid
核显方案:Intel GVT-g
虚拟机系统:
DSM (群晖)
Windows
FNOS
二、问题现象
在使用 GVT-g 插件分配核显时:
DSM ✅ 正常
Windows ✅ 正常
FNOS ❌ 直接报错,无法进入系统
三、问题分析 & 解决过程
这个问题并不是单一原因导致,而是多个因素叠加,我分阶段排查出来:
1️⃣ FNOS 镜像版本问题(关键坑)
我最开始使用的是:
FNOS 0.8 早期版本 ISO
结果:
一旦分配 GVT-g 核显 → 直接无法启动
后来测试发现:
👉 问题本质:引导 + 内核版本过旧
不仅 FNOS:
Debian 老版本也存在同样问题
✅ 解决方案:
更换 最新版本 FNOS ISO 镜像
✔️ 结果:
不再报错,可以正常启动虚拟机
⚠️ 但此时:
👉 仍然无法真正调用核显(只是“不报错”)2️⃣ Unraid VM XML 配置问题(核心关键点)
当虚拟机能正常启动后,我开始排查为什么核显无法被识别。
查阅 FNOS 论坛后发现,需要手动修改 fons 虚拟机的 XML 配置。
找到
节点,修改为: ⚠️ 关键点:
👉 这一行是关键中的关键!
为什么重要?
FNOS 对 PCI 设备位置有“隐式依赖”:
默认期望核显出现在 00:02.0
如果不手动指定:
会识别失败
3️⃣ i915 驱动参数问题(最终生效关键)
即使前两步完成,FNOS 仍然可能无法正常使用核显。
最终还需要修改 i915 驱动参数:
ssh 登录 fnos 系统后台,使用 root 权限进行如下操作echo “options i915 enable_guc=0” > /etc/modprobe.d/i915.conf
update-initramfs -u
reboot⚠️ 为什么要这样做?
GVT-g 环境下:
enable_guc 默认开启可能导致冲突
关闭后:
i915 更稳定
核显才能正常工作
四、最终效果
完成以上三步后:
系统 核显状态
Windows ✅ 正常
FNOS ✅ 正常👉 成功实现:
多虚拟机共享核显
硬件加速正常调用
注意:
unraid 下的核显虚拟化有可能会导致 windows 虚拟机长时间运行卡死,导致 cpu 占用率其高,最终无法登录 unraid 的 webui 的情况。
我现在的解决办法是 windows 虚拟机内装了个定时关机插件,每天到凌晨 2 点关闭 windows 虚拟机,要用的时候再启动,目前稳定使用一年没出现过问题
作者: roykingH | 发布时间: 2026-03-20 09:27
44. 想买国内 coding plan 的这会儿可以去看看百度千帆
各大厂家天天被抢完,百度今天这个点儿竟然还有货,点击付款后,发现我还有个不知道哪儿来的 20 元代金券,总共付了 20
作者: listenerri | 发布时间: 2026-03-20 07:05
45. DDD 是不是已经死了?
最近在重构老项目,想问一下现在还有没有必要用 DDD 那套来重构呢? go 语言加 DDD 配合 ai 变成会不会有意想不到的效果?
作者: xing4576 | 发布时间: 2026-03-20 01:44
46. Netcatty - 开源免费的 SSH 终端软件, 使用 AI 加速你的日常运维工作
前情提要
https://www.v2ex.com/t/1195002
摘要如下:
之前我一直在付费用 Termius ,不过后来总觉得,每个月花 15 刀买一个 SSH Client ,还是有点贵。中间也调研过不少平替,但找来找去,除了 Termius 之外,确实没发现第二款支持云同步、同时体验也比较完整的 SSH Client 。于是就想着,干脆自己 vibe 一个出来。
Netcatty 支持多种云同步方式,包括 Google Drive 、Github Gist 、OneDrive 、S3 、WebDav 。同步基本是实时的,只要配置发生变化,就会自动同步到云端。功能上,Netcatty 已经实现了 Termius 的大部分核心能力,交互和布局也参考了 Termius 。如果你本来就是 Termius 老用户,上手 Netcatty 应该会非常自然。
不过,FIDO2 / 生物指纹密钥这部分我暂时还没有做;另外,Netcatty 目前也还不支持移动端。
如果你刚好需要一个带云同步功能的 SSH Client ,同时也觉得 Termius 价格有点高,而且暂时没有移动端需求,那么可以试试这个开源平替。省下来的钱,说不定还能再买一个 AI 订阅 😘
这个项目的定位一直很明确,就是做一个 Termius 的开源平替。后续也不会收费,平时我也会一边自用、一边顺手修 bug 、补功能。如果它刚好能帮到你,也欢迎给项目点个 star ,就当交个朋友。
上次在 V2EX 发帖之后,挺意外地收到了很多 V 友的鼓励和认可,也有不少朋友认真提了很多建议。过去大概 20 天里,我又继续 vibe coding 了一阵,把 Netcatty 在功能和易用性做了很多改进。 所以这次想重新开个贴,和大家汇报一下这段时间的新进展,也顺便再把它分享给更多有需要的朋友。
使用 AI ,更高效地驱动你的日常运维工作
在花了不少时间把一个终端软件该有的基础功能慢慢补齐之后,我开始意识到:是时候把 AI 加进 Netcatty 了。于是又花了大概一个星期,认真 vibe coding 了一版 AI 相关功能。
关于 AI 应该以什么形态出现,我其实没有想得太复杂。像 Warp 那种比较重的交互形态,我个人会觉得还是有一点理解门槛。对我来说,更自然的方式是:在 terminal 旁边放一个聊天框,你直接告诉 AI 你想做什么,它就帮你操作。简单、直接,也更符合日常使用习惯。
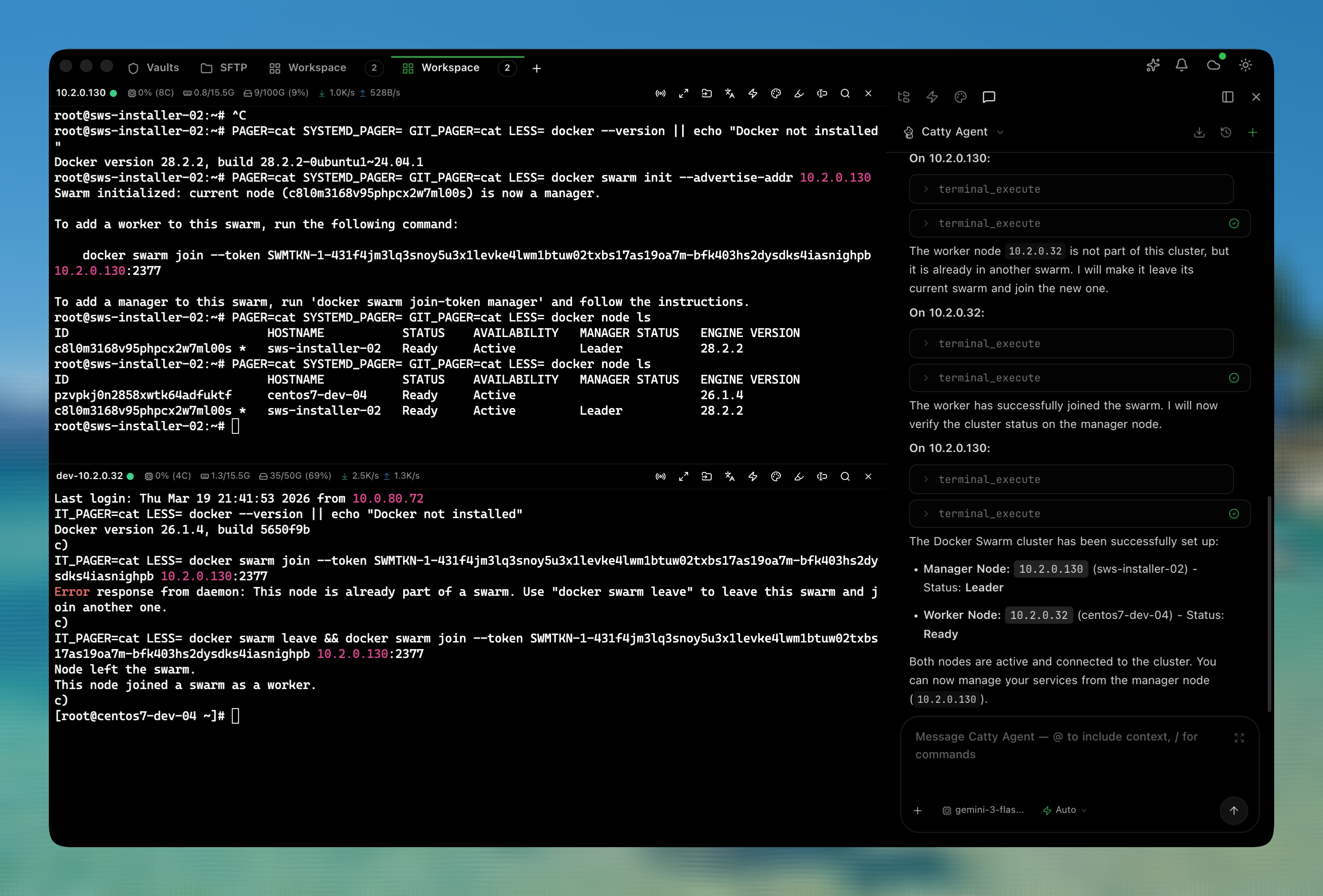
基于这个思路,我先做出了一版可用的形态。下面这张图里的例子,就是让 AI 帮我把两台 server 组一个集群。
这个能力其实能覆盖很多很实用的场景。比如前段时间,我让 AI 帮我在海外节点上做部署,整个过程非常丝滑,到了最后,它甚至直接把配置文件都给出来了,省掉了很多来回切换和查资料的时间。
目前 Model Provider 这块已经支持主流的模型提供商,同时也接入了本地的 Claude Code 和 Codex (通过 ACP 协议桥接到 Netcatty ) 这意味着,如果你本地已经在使用 Claude Code 或 Codex ,基本不需要再做额外折腾,就可以把它们无缝接进 Netcatty ,让 AI 直接帮你操作服务器。
当然,现在也已经支持 web-search 和 web-fetch 。你既可以直接接成熟的 SaaS 方案,比如 Tavily ,也可以根据自己的需求,在本地自建 search provider 。
这部分的典型场景是:比如你在网上看到一篇帖子、一段教程,甚至是一段报错信息,都可以直接发给 AI ,让它结合终端环境去帮你处理。 而且当 AI 遇到不确定的概念、命令或者上下文时,它也会主动去网上搜索,再继续执行后续操作。
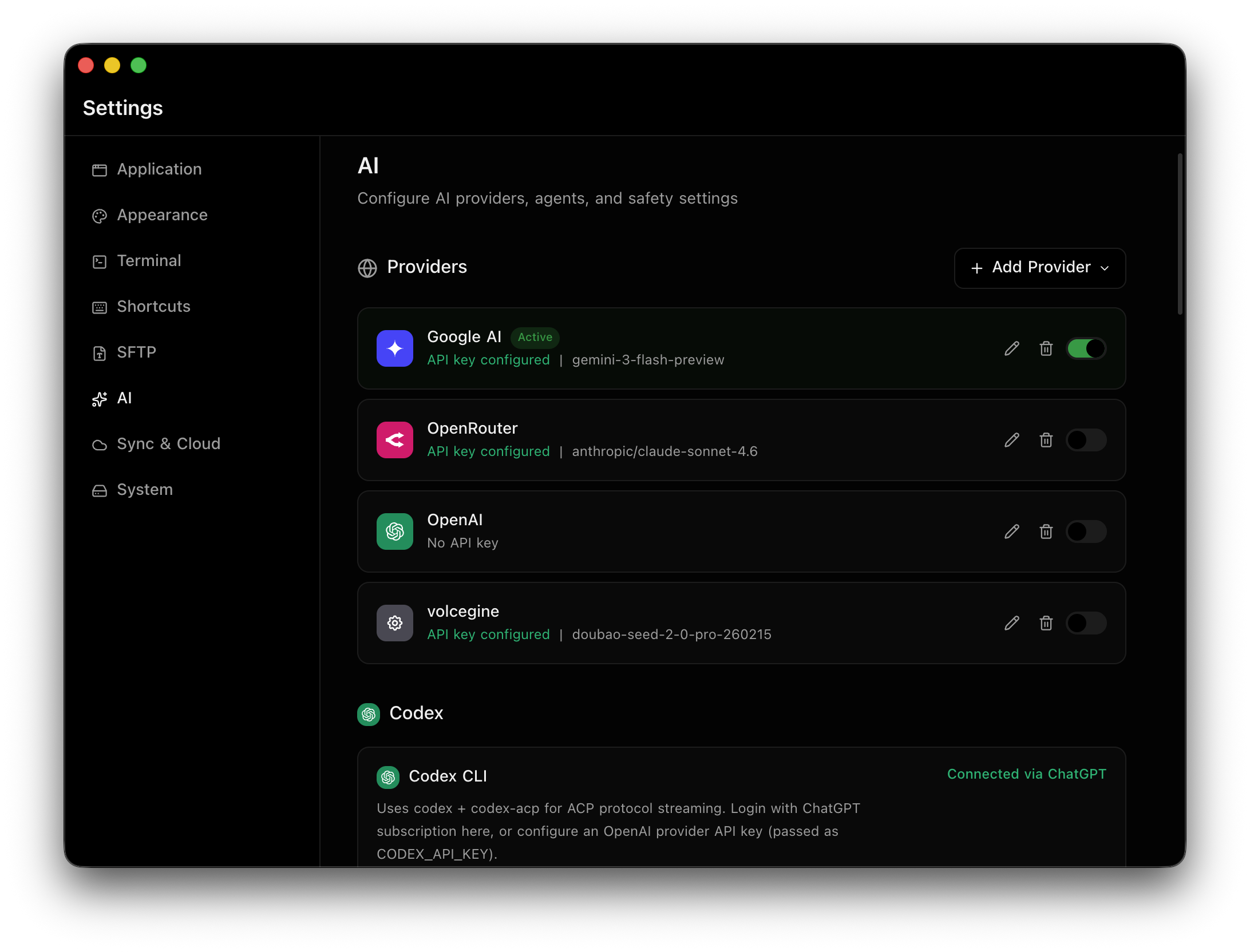
UI 优化
除了 AI 之外,这段时间我也顺手把 Netcatty 的整体 UI 做了一轮新的打磨。 相比之前的版本,现在整体观感会更现代一些,布局也更清爽,日常使用时的体验会舒服不少。
后记
最后,还是想认真感谢一下之前支持 Netcatty 的 V 友们。
上次发帖之后,大家给了我很多鼓励支持。我后来试着拿 Netcatty 去申请了 OpenAI 的开源软件支持计划。没想到居然意外通过了,这件事对我来说,确实算是一个小小的鼓舞。
也因为这点鼓励,我后来斥巨资买了 Apple 开发者资格😂,给 Netcatty 的 mac 客户端做了签名。 接下来,Netcatty 的桌面客户端依然会继续保持开源和免费。希望它能在你日常连接服务器、处理运维工作的时候,多少带来一点方便,也少一点折腾。
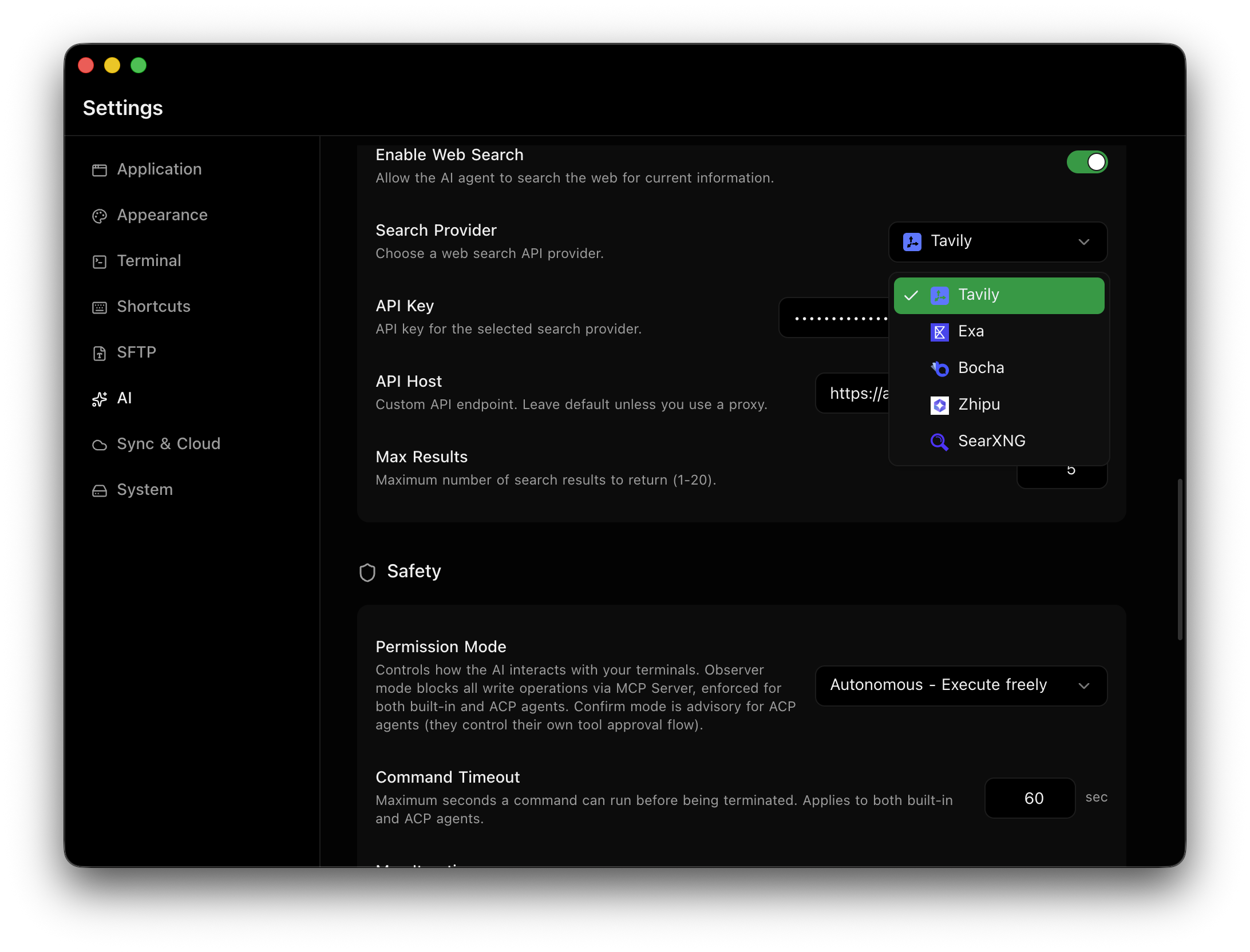
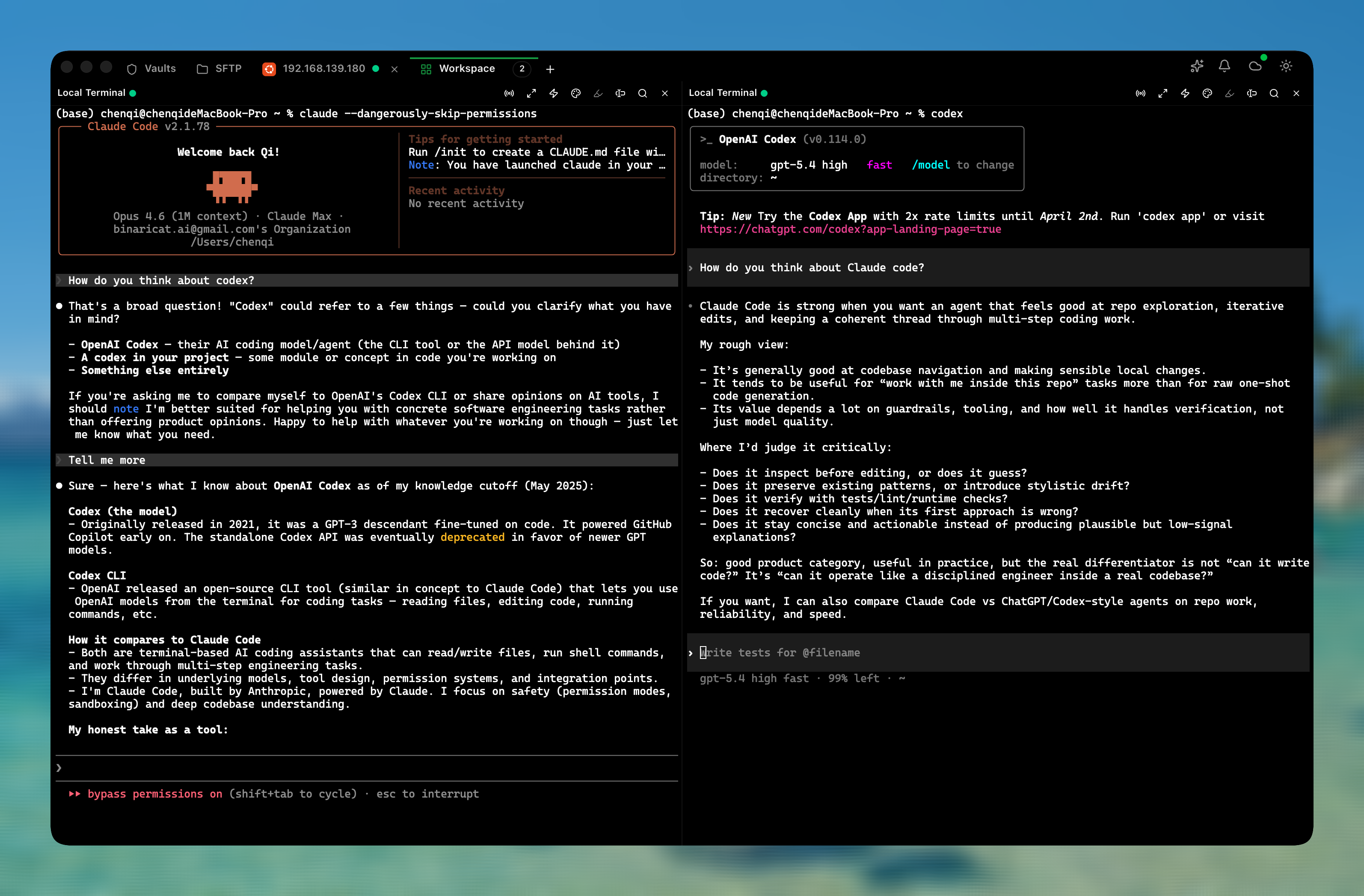
作者: BigcatChen | 发布时间: 2026-03-20 03:31
47. VSCode 使用 Cline(或者其它)对接 Vibe Coding 的 API,怎么做到隐私账号和代码隔离?
用的是中转 API ,要 Vibe 项目时,很多行为都要围绕一些 url ,公网 IP ,密钥来进行调试和编写的,这些资源给个低权受限的也干不了活,因为中转 API ,还是不想泄出去,大家是怎么做安全隔离的?
作者: qazwsxkevin | 发布时间: 2026-03-20 09:33
48. 开发了一个小工具, OpenClaw gateway 老挂?用这个 CLI 自动守活| v0.6.1
人在外面,和 OpenClaw 对话结果已挂,所以写了一个 watch dog 程序
你是不是也遇到过:
- AI 正在跑任务,突然没响应
- 回终端一看,gateway 早就挂了
- 没告警、没重启,只能手动救火
每次都敲
openclaw gateway restart,真的很烦。直接上工具:openclaw-cli
一句话:让 OpenClaw 挂了就自动起,省心。
npm install -g openclaw-cli https://openclaw-cli.app/
作者: sobranie | 发布时间: 2026-03-20 06:14
49. 红米 15 5G 海外版无论如何都无法连接 Mac 传输文件。
人在海外长居,才入手红米 15 5G 海外版,可是连接我的 Macbook Pro M1 Max ,把手机端已经设置为”文件传输模式“,无论如何都无法用 OpenMTP 连接传输文件,Tahoe 完全无法识别手机,Mac AppStore 里的 Xiaomi Interconnectivity 无法连接系统为 Hyper OS 2 的红米 15 5G 。请问有好的有线传输的解决方案吗?谢谢。
作者: Phycheez | 发布时间: 2026-03-20 09:15
50. [理性讨论] 国产御三家的编程模型里面, 真正能咬住国外第一梯队的,也就 KIMI 和 GLM 吧
MiniMax 的每次发布都是拳打 GPT 最强模型,脚踢 Claude 最强模型,实际一坨。加上劈头盖脸的宣发,让人生厌。感觉单纯沦为拉伸股价的工具了。
作者: frantic | 发布时间: 2026-03-20 03:00